
grep
grep(global search regular expression(RE) and print out the line
以下来自ZYF师兄的讲义
什么是grep
grep可以快速有效地从输入或者文件里查找所需的字符串
grep [options] [regexp] [filename]
[options]:
-i 忽略大小写
-w 只匹配整个单词
-r 递归读取目录下的每个文件
-v 输出不匹配的行
-H
-L
-A num
-B num
-C num
-q
正则表达式基础
•字符匹配
•字数匹配
•位置锚定
•分组引用
字符匹配:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
支持POSIX CLASS里的字符

匹配次数(贪婪模式):
* 匹配其前面的字符任意次
a, b, ab, aab, acb, adb, amnb
a*b, a?b
a.*b
.* 任意长度的任意字符
\? 匹配其前面的字符1次或0次
\{m,n\} 匹配其前面的字符至少m次,至多n次
\{1,\}
\{0,3\}
位置锚定:
^ 锚定行首,此字符后面的任意内容必须出现在行首
$ 锚定行尾,此字符前面的任意内容必须出现在行尾
^$ 空白行
\<或\b 锚定词首,其后面的任意字符必须作为单词首部出现
\>或\b 锚定词尾,其前面的任意字符必须作为单词的尾部出现
分组引用:
\(\)
\(ab\)*
后向引用
\1: 引用第一个左括号以及与之对应的右括号所包括的所有内容
\2:
\3:
like-->liker
love-->lover
like-->Like
love-->Love
测试:
bboxh@DESKTOP-DEEP:~$ echo 'like-->liker' | grep '\(like\).*\1'
like-->liker
扩展正则表达式
字符匹配:
.
[]
[^]
次数匹配:
*:
?:
+: 匹配其前面的字符至少1次
{m,n}
位置锚定:
^
$
\<
\>
分组:
():分组
\1, \2, \3, ...
或者
| or
C|cat Cat或cat, C或cat
练习:
1.邮箱格式匹配
2.IP地址匹配
3.用户名匹配
4.手机号码匹配
5.Any things
项目实战(根据时间充裕情况,可选讲解):
1.判断网络是否通 ping
2.获取网卡地址 ifconfig
3.获取内存使用率 free
4.获取CPU的负载情况 w
5.获取CPU的空闲率 vmstat
===================================================
grep的正则模式
以下来自 grep --help
版本 grep (GNU grep) 3.0
正则表达式选择与解释:
-E, --extended-regexp PATTERN 是一个可扩展的正则表达式(缩写为 ERE)
-F, --fixed-strings PATTERN 是一组由断行符分隔的字符串。
-G, --basic-regexp PATTERN 是一个基本正则表达式(缩写为 BRE)
-P, --perl-regexp PATTERN 是一个 Perl 正则表达式
-e, --regexp=PATTERN 用 PATTERN 来进行匹配操作
-f, --file=FILE 从 FILE 中取得 PATTERN
-i, --ignore-case 忽略大小写
-w, --word-regexp 强制 PATTERN 仅完全匹配字词
-x, --line-regexp 强制 PATTERN 仅完全匹配一行
-z, --null-data 一个 0 字节的数据行,但不是空行
杂项:
-s, --no-messages 不显示错误信息
-v, --invert-match 选中不匹配的行
-V, --version 显示版本信息并退出
--help 显示此帮助并退出
输出控制:
-m, --max-count=NUM NUM 次匹配后停止
-b, --byte-offset 输出的同时打印字节偏移
-n, --line-number 输出的同时打印行号
--line-buffered 每行输出清空
-H, --with-filename 为每一匹配项打印文件名
-h, --no-filename 输出时不显示文件名前缀
--label=LABEL 将LABEL 作为标准输入文件名前缀
-o, --only-matching 只显示匹配PATTERN 部分的行
-q, --quiet, --silent 不显示所有常规输出
--binary-files=TYPE 设定二进制文件的TYPE 类型;
TYPE 可以是`binary', `text', 或`without-match'
-a, --text 等同于 --binary-files=text
-I 等同于 --binary-files=without-match
-d, --directories=ACTION 读取目录的方式;
ACTION 可以是`read', `recurse',或`skip'
-D, --devices=ACTION 读取设备、先入先出队列、套接字的方式;
ACTION 可以是`read'或`skip'
-r, --recursive 等同于--directories=recurse
-R, --dereference-recursive 同上,但遍历所有符号链接
--include=FILE_PATTERN 只查找匹配FILE_PATTERN 的文件
--exclude=FILE_PATTERN 跳过匹配FILE_PATTERN 的文件和目录
--exclude-from=FILE 跳过所有除FILE 以外的文件
--exclude-dir=PATTERN 跳过所有匹配PATTERN 的目录。
-L, --files-without-match 只打印不匹配FILEs 的文件名
-l, --files-with-matches 只打印匹配FILES 的文件名
-c, --count 只打印每个FILE 中的匹配行数目
-T, --initial-tab 行首tabs 分隔(如有必要)
-Z, --null 在FILE 文件最后打印空字符
文件控制:
-B, --before-context=NUM 打印文本及其前面NUM 行
-A, --after-context=NUM 打印文本及其后面NUM 行
-C, --context=NUM 打印NUM 行输出文本
-NUM 等同于 --context=NUM
--color[=WHEN],
--colour[=WHEN] 使用标记高亮匹配字串;
WHEN 可以是`always', `never'或`auto'
-U, --binary 不要清除行尾的CR 字符(MSDOS/Windows)
-u, --unix-byte-offsets 忽略CR 字符,报告字节偏移
(MSDOS/Windows)
'egrep' 即'grep -E'。'fgrep' 即'grep -F'。
直接调用'egrep' 或是'fgrep' 均已被废弃。
若FILE 为 -,将读取标准输入。不带FILE,读取当前目录,除非命令行中指定了-r 选项。
如果少于两个FILE 参数,就要默认使用-h 参数。
如果有任意行被匹配,那退出状态为 0,否则为 1;
如果有错误产生,且未指定 -q 参数,那退出状态为 2。
grep有三种正则模式
-E, --extended-regexp PATTERN 是一个可扩展的正则表达式(缩写为 ERE)
-G, --basic-regexp PATTERN 是一个基本正则表达式(缩写为 BRE)
-P, --perl-regexp PATTERN 是一个Perl 正则表达式(缩写为 PRE)
基础模式 ( ) { } + ? | 都必须转义使用
基础和扩展模式不支持分组匹配里的 零宽断言
几种POSIX流派的说明
|
流派
|
说明
|
工具
|
|
BRE
|
(、)、{、}都必须转义使用,不支持+、?、|
|
grep、sed、vi(但vi支持这些多选结构和反向引用)
|
|
GNU BRE
|
(、)、{、}、+、?、|都必须转义使用
|
GNU grep、GNU sed
|
|
ERE
|
元字符不必转义,+、?、(、)、{、}、|可以直接使用,\1、\2的支持不确定
|
egrep、awk
|
|
GNU ERE
|
元字符不必转义,+、?、(、)、{、}、|可以直接使用,支持\1、\2
|
grep –E、GNU awk
|
Linux/Unix工具与正则表达式的POSIX规范
http://www.infoq.com/cn/news/2011/07/regular-expressions-6-POSIX
==============================================
正则表达式教程
正则表达式30分钟入门教程
https://deerchao.net/tutorials/regex/regex.htm
元字符
表1.常用的元字符
代码 说明
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
限定符
表2.常用的限定符
代码/语法 说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
方括号[] 指定一个字符范围
分枝条件 满足其中任意一种规则都应该当成匹配,具体方法是用 | 把不同的规则分隔开
分组 可以用小括号来指定子表达式
反义
表3.常用的反义代码
代码/语法 说明
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是单词开头或结束的位置
[^x] 匹配除了x以外的任意字符
[^aeiou] 匹配除了aeiou这几个字母以外的任意字符
后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
后向引用用于重复搜索前面某个分组匹配的文本
| 分类 | 代码/语法 | 说明 |
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (?<!exp) | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
零宽断言
用于查找在某些内容(但并不包括这些内容)之前或之后的东西,用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。
比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
(
正则(?:exp)的作用
http://bbs.csdn.net/topics/120096404
(?:exp) 非捕获组,匹配exp的内容,但不捕获到组里
至于作用,一般来说是为了节省资源,提高效率
比如说验证输入是否为整数,可以这样写
^([1-9][0-9]*|0)$
这时候我们需要用到()来限制“|”表示“或”关系的范围,但我们只是要判断规则,没必要把exp匹配的内容保存到组里,这时就可以用非捕获组了
^(?:[1-9][0-9]*|0)$
)
==============================================
sed&awk
以下来自ZYF师兄的讲义
What sed?
sed: stream editor for filtering and transforming text
Sed Basic usage
sed options 'AddressCommand' file ....options
Address
Command
Address:
1.Startline,Endline 匹配起始和结束
1,100
$ 表⽰示最后⼀一⾏
2./Pattern(RegExp)/ 匹配模式的⾏
/^root/
3./Pattern1/,/Pattern2/ 第一匹配到⾏pattern1,到第一次匹配到patter2
4.LineNumber 指定⾏行
5.startline,+N
从startline开始,向后的N⾏
Command:
d: 删除模式空间中符合条件的行
p: 输出模式空间中符合条件的行
a \string: 在指定的行后面追加新行
i\string: 在指定行的前面添加新行
r FILE: 将FILE文件中的内容追加到符合条件的行后面
w FILE: 将匹配的行保存到FILEL文件中
s/pattern/string/: 查找并替换,默认只替换每行第一次匹配到的字符
加修饰符:
g: 全局替换
i: 忽略字符大小写
分隔符可以是其他字符@,#
支持分组引用
注意: ;号用来实现多个命令
Sed Advance usage
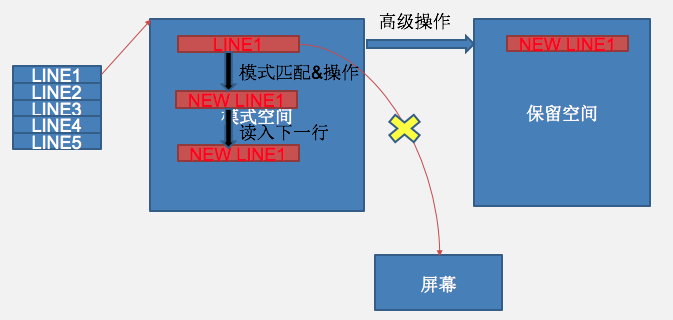
Command:
+ g:[address[,address]]g 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
+ G:[address[,address]]G 将hold space中的内容append到pattern space\n后
+ h:[address[,address]]h将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
+ H:[address[,address]]H 将pattern space中的内容append到hold space\n后
+ d:[address[,address]]d 删除pattern中的所有行,并读入下一新行到pattern中
+ D:[address[,address]]D 删除multiline pattern中的第一行,不读入下一行
+ x: 交换模式空间和Hold空间的内容
sed '1!G;h;$!d' filename
Linux Hacker 不断提升自己逼格为己任
1. 在每一行后面增加空行
sed G
2. 删除空行
sed '/^$/d'
3. 在匹配到的行后插入一行
sed '/pattern/G'
4. 对文件的每一行进行编号
sed ‘=’ /etc/passwd|sed'N;s/\n/\t/'
5. 计算文本行数
sed -n '$=' /etc/passwd
6. 删除每行前导的空白字符
sed 's/^[[::space]]*//'
7. 删除每行的行尾的空白字符
sed 's/[[:space:]]*$//'
8. 倒置所有行(模拟tac)
sed '1!G;h;$!d'
sed -n '1!G;h;$p'
9. 两行连接成一行
sed 'N;s/\n/ /'
10. 删除文件顶部的所有空行
sed '/./,$!d'
What Awk
Pattern scanning and processig language
The report generator
Awk is a convenient and expressive programming language
(后面太多了,不看了)
============================================================
sed
sed不支持非贪婪匹配(?),只能使用[^符号]来最小匹配
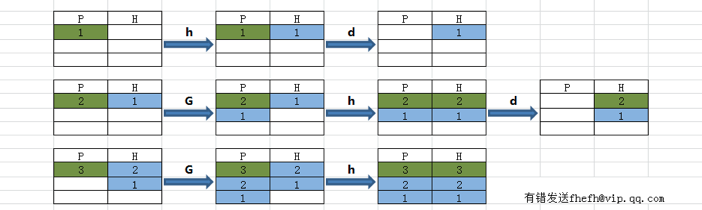
第二个示例,反序了一个文件的行:
|
1
2
3
4
|
$ sed '1!G;h;$!d' t.txt
three
two
one
|
其中的 ‘1!G;h;$!d’ 可拆解为三个命令
- 1!G —— 只有第一行不执行G命令,将hold space中的内容append回到pattern space
- h —— 第一行都执行h命令,将pattern space中的内容拷贝到hold space中
- $!d —— 除了最后一行不执行d命令,其它行都执行d命令,删除当前行
==============================================================
实例:
sed -n -e '1,/^exit 0$/!p' $0 > ${MYPATH}/${PROJECT_NAME}.tar.gz
用sed解析run包。
通过sed把第一行直到exit 0行删除,然后输出到tar.gz,即把后面压缩数据的部分输出。
