
19、Java技术扩展【Hadoop8天】
第一天 hadoop的基本概念 伪分布式hadoop集群安装 hdfs mapreduce 演示
第二天 hdfs的原理和使用操作、编程
第三天 mapreduce的原理和编程
第四天 常见mr算法实现和shuffle的机制
第五天 hadoop2.x中HA机制的原理和全分布式集群安装部署及维护
第六天 hbase hive
第七天 storm+kafka
第八天 实战项目
hadoop是什么? 第一天
解决问题:
•海量数据的存储(HDFS)
•海量数据的分析(MapReduce)
•资源管理调度(YARN)
(
下载安装CENTOS 7
aria2c.exe -x5 -j5 http://mirrors.aliyun.com/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1611.iso
-x 同一服务器最大同时请求数 -j线程数
发现增加-x对速度提高大
不下了,教程里有
参考 hadoop2.4.1伪分布式搭建.txt
解压 CentOS.zip,重命名为 CentOS_Hadoop
启动 用户名hadoop 密码hadoop
设置静态ip 192.168.50.130 255.255.255.0 192.168.50.2 8.8.8.8
在/etc/sudoers里加入 hadoop用户
sudo service network restart
/etc/inittab 改为 id:3:initdefault: 默认启动命令行多用户模式
装JAVA
展【Hadoop8天】/weekend110-第1天/笔记文档软件$ scp.exe jdk-7u65-linux-i586.tar.gz hadoop@192.168.50.130:~/
tar xzf jdk-7u65-linux-i586.tar.gz
将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
安装tmux
参考 https://www.zybuluo.com/mwumli/note/149542
wget https://cloud.github.com/downloads/libevent/libevent/libevent-2.0.21-stable.tar.gz
...
sudo yum install ncurses-devel
展【Hadoop8天】/weekend110-第1天/笔记文档软件$ scp tmux-2.4.tar.gz hadoop@192.168.50.130:~/
)
配置hadoop
hadoop2.4.1伪分布式搭建.txt
hadoop-env.sh
配置JAVA_HOME环境变量 (虽然env里有,但是不配置还是会出错)
core-site.xml
指定HADOOP所使用的文件系统schema(URI),HDFS的老大
指定hadoop运行时产生文件的存储目录
hdfs-site.xml
指定HDFS副本的数量
mapred-site.xml
指定mr运行在yarn上
yarn-site.xml
指定YARN的老大(ResourceManager)的地址
reducer获取数据的方式
关闭防火墙
sudo service iptables stop
关闭当前登录模式防火墙的状态
sudo chkconfig iptables off
查看不同登录模式防火墙的状态
sudo chkconfig iptables --list
将hadoop添加到环境变量
/home/hadoop/app/hadoop-2.4.1
格式化namenode
hdfs namenode -format (hadoop namenode -format)
启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.50.130:50070 (HDFS管理界面)
http://192.168.50.130:8088 (MR管理界面)
上传文件到hdfs
hadoop fs -put tmux-2.4.tar.gz hdfs://hadoop1:9000/
(
hadoop fs -put tmux-2.4.tar.gz hdfs://localhost:9000/
出错
core-site.xml里的 fs.defaultFS
yarn-site.xml里的yarn.resourcemanager.hostname
必须写绝对地址,写localhost之后异地访问会吃出错
还要配置node名称
etc/hadoop/slaves 这是配置datanodes的
还是不行
是/etc/host 的问题
192.168.50.130 hadoop1
不能写127.0.0.1
)
ssh免密码登录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
cat id_rsa.pub >> authorized_keys
sudo vim /etc/ssh/sshd_config
sudo service sshd restart
.ssh/authorized_keys的权限必须要设置为644
id_rsa的权限设置为600
mapreduce程序例子
位置 /home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce
计算圆周率
hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 5
统计单词出现次数
vim test.txt
hadoop fs -mkdir /wordcount
hadoop fs -mkdir /wordcount/input
hadoop fs -put test.txt /wordcount/input/
运行
hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /wordcount/input /wordcount/output/
查看结果
hadoop fs -ls /wordcount/output
hadoop fs -cat /wordcount/output/part-r-00000
HDFS的架构
主从结构
•主节点, namenode
•从节点,有很多个: datanode
namenode负责:
•接收用户操作请求
•维护文件系统的目录结构
•管理文件与block之间关系,block与datanode之间关系
datanode负责:
•存储文件
•文件被分成block存储在磁盘上
•为保证数据安全,文件会有多个副本
HDFS的实现思想
- hdfs通过分布式集群来存储文件
- 文件存储到hdfs集群中取的时候被分成block
- 文件的block存放在若干台datanode节点上
- hdfs文件系统中的文件与真实block之间有映射关系,由namenode管理
- 每一个block在集群中会存储多个副本,好处是可以提高数据的可靠性,还可以提高访问的吞吐量
hdfs的shell操作
[hadoop@hadoop1 mapreduce]$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...] 创建空文件,touch
[-usage [cmd ...]]
hdfs不支持修改文件内容
hdfs中文件夹是元数据,不是文件
第二天
存很多小文件缺点 占用元数据空间 占用存储空间
- NameNode元数据管理机制
NN editslog fsimage client
- 客户端上传文件时,NN首先往edits log文件中记录元数据操作日志
- 客户端开始上传文件,完成后返回成功信息给NN,NN就在内存中写入这次上传操作的新产生的元数据信息
- 每当editslog写满时,需要将这一段时间的新的元数据刷到fsimage里去
+--NN-----------------------+
| +--内存------+ |
| | meta.data | |
| +-------------+ |
| +---------+ +---------+ |
| | fsimage | |edits.new | |
| | | +---------+ |
| | | +---------+ |
| +---------+ |edits | |
| +---------+ |
+-----------------------------+
将editslog和fsimage合并,由second namenode做的
- secondary namenode的工作流程
1.secondary通知namenode切换edits文件
2.secondary从namenode获得fsimage和edits(通过http)
3.secondary将fsimage载入内存,然后开始合并edits
4.secondary将新的fsimage发回给namenode
5.namenode用新的fsimage替换旧的fsimage
什么时候checkpiont
- fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
- fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
- Datanode的工作原理
提供真实文件数据的存储服务。
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
dfs.block.size
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
Replication。多复本。默认是三个。
hdfs-site.xml的dfs.replication属性
- Remote Procedure Call
lRPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
RPC采用客户机/服务器模式。
hadoop的整个体系结构就是构建在RPC之上的(见org.apache.hadoop.ipc)。
- HDFS的JAVA客户端编写
先启动hdfs
./start-dfs.sh && ./start-yarn.sh
[hadoop@hadoop1 hadoop-2.4.1]$ hadoop fs -ls /
Found 5 items
-rw-r--r-- 1 hadoop supergroup 143588167 2017-05-24 07:59 /jdk-7u65-linux-i586.tar.gz
drwx------ - hadoop supergroup 0 2017-05-23 23:31 /tmp
-rw-r--r-- 1 hadoop supergroup 470549 2017-05-23 22:36 /tmux-2.4.tar.gz
drwxr-xr-x - hadoop supergroup 0 2017-05-23 23:31 /user
drwxr-xr-x - hadoop supergroup 0 2017-05-23 23:39 /wordcount
启动成功
打开eclipse创建项目hadoop1
创建依赖库集合hdfslib
位置 /home/hadoop/app/hadoop-2.4.1/share/hadoop/hdfs
包含hdfs依赖
share/hadoop/hdfs/hadoop-hdfs-2.4.1.jar
以及hdfs需要的依赖
share/hadoop/hdfs/lib/*
以及hadoop common依赖
share/hadoop/common/hadoop-common-2.4.1.jar
以及hadoop common需要的依赖
share/hadoop/common/lib/*
编写代码
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path src = new Path("hdfs://hadoop1:9000/jdk-7u65-linux-i586.tar.gz");
FSDataInputStream in = fs.open(src);
FileOutputStream os = new FileOutputStream("./jdk-7u65-linux-i586.tar.gz");
IOUtils.copy(in, os);
报错
Exception in thread "main" java.lang.IllegalArgumentException: Wrong FS: hdfs://hadoop1:9000/jdk-7u65-linux-i586.tar.gz, expected: file:///
因为没有配置正确
添加 core-site.xml 不知道为什么不行,只好在代码里添加
conf.set("fs.defaultFS", "hdfs://hadoop1:9000");
下载成功
上传文件用
FSDataOutputStream os = fs.create(dst);
......
IOUtils.copy(is, os);
或者
fs.copyToLocalFile(src, dst);
下载文件用
FSDataInputStream in = fs.open(src);
......
IOUtils.copy(in, os);
或者
fs.copyToLocalFile(src, dst);
设置操作用户名
VM arguments:-DHADOOP_USER_NAME=hadoop
或者
fs = FileSystem.get(new URI("hdfs://weekend110:9000/", conf, "hadoop"));
文件夹操作
fs.mkdirs(new Path("/abc"));
fs.delete(new Path("/abc") );
fs.listFiles(new Path("/abc", true)); //是否递归
- Hadoop中的RPC应用实例
服务代理类 LoginServiceInterface.java
服务实现类 LoginServiceImpl.java
服务端start.java
Builder builder = new RPC.Builder(new Configuration()); builder.setBindAddress("localhost").setPort(10000).setProtocol(LoginServiceInterface.class).setInstance(new LoginServiceImpl());
Server server = builder.build();
server.start();
客户端LoginContorller.java
LoginServiceInterface proxy = RPC.getProxy(LoginServiceInterface.class, 1L, new InetSocketAddress("localhost", 10000), new Configuration());
String result = proxy.login("angelababy", "123456");
System.out.println(result);
- hdfs下载数据源码分析
FileSystem fs = FileSystem.get(conf);调用过程
private static FileSystem createFileSystem(URI uri, Configuration conf
) throws IOException {
Class<?> clazz = getFileSystemClass(uri.getScheme(), conf);
if (clazz == null) {
throw new IOException("No FileSystem for scheme: " + uri.getScheme());
}
FileSystem fs = (FileSystem)ReflectionUtils.newInstance(clazz, conf);
fs.initialize(uri, conf);
return fs;
}
4.HDFS源码分析
例子中FileSystem是DistributedFileSystem
this.dfs = new DFSClient(uri, conf, statistics);
DFSClient里初始化了namenode的代理对象
FileSystem.get --> 通过反射实例化了一个DistributedFileSystem --> new DFSCilent()把他作为自己的成员变量
在DFSClient构造方法里面,调用了createNamenode,使用了RPC机制,得到了一个NameNode的代理对象,就可以和NameNode进行通信了
FileSystem --> DistributedFileSystem --> DFSClient --> NameNode的代理
第三天
- hdfs打开输入流源码分析
FileSystem fs = FileSystem.get(conf); //DistributedSystem
DistributedFileSystem{
DFSClient dfs;
}
DFSInputStream is = fs.open(path);
DistributedFileSystem.dfs.open(path){
return new DFSInputStream(this, src, buffersize, verifyVhecksum);
openInfo();
}
//获取文件块信息
openInfo(){
//这里完成对locatedBlocks赋值
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();
}
在new DFSInputStream里面
private dfsClient = this;
private src = src;
buffersize = buffersize;
//以下成员在openInfo()中赋值
private locatedBlocks;
private blockReader;
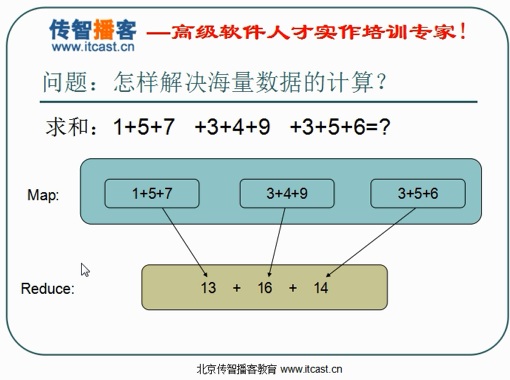
- mapreduce介绍和wordcount
WCMapper.java
//4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
//map 和 reduce 的数据输入输出都是以 key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
输入类型是框架传给我们的,我们不能改变。
分别是Long和String。Long是起始偏移量。
但是使用自带的String和Long,序列化后的信息太多,不适合网络传输。
Hadoop实现了自己的一套序列化机制,LongWritable和Text
然后重写map方法
context.write(new Text(word), new LongWritable(1));
WCReducer.java
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
//框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法
//<hello,{1,1,1,1,1,1.....}>
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
重写reduce方法
context.write(key, new LongWritable(count));
WCRunner.java
org.apache.hadoop.mapred 是老版本的
org.apache.hadoop.mapreduce 是新版本的,我们使用这个包里的类
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//设置整个job所用的那些类在哪个jar包
wcjob.setJarByClass(WCRunner.class);
//本job使用的mapper和reducer的类
wcjob.setMapperClass(WCMapper.class);
wcjob.setReducerClass(WCReducer.class);
//指定reduce的输出数据kv类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class);
//指定mapper的输出数据kv类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class);
//指定要处理的输入数据存放路径 new Path("/wc/srcdata")
FileInputFormat.setInputPaths(wcjob, new Path("hdfs://hadoop1:9000/wc/srcdata/"));
//指定处理结果的输出数据存放路径 new Path("wc/output3")
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hadoop1:9000/wc/output3/"));
//将job提交给集群运行
wcjob.waitForCompletion(true);
}
设置setJarByClass找到jar包在哪。
原理:通过设置的类的classLoader找到其所在的jar包
导出jar包到集群里运行
scp wc.jar hadoop@192.168.50.130:~/
需要启动 hdfs 和 yarn
start-dfs.sh && start-yarn.sh
[hadoop@hadoop1 app]$ hadoop fs -mkdir /wc/srcdata
[hadoop@hadoop1 app]$ hadoop fs -mkdir /wc/output3
mv ../wc.jar ./
[hadoop@hadoop1 app]$ hadoop fs -put words.log /wc/srcdata
[hadoop@hadoop1 app]$ hadoop jar wc.jar com.example.hadoop.mr.wordcount.WCRunner
报错了
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/example/hadoop/mr/wordcount/WCRunner : Unsupported major.minor version 52.0
是因为虚拟机集群里的java版本1.7比编译时的1.8低。
在eclipse右键调整项目编译兼容性为1.7既可以。
[hadoop@hadoop1 app]$ hadoop fs -ls /wc/output3
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2017-06-17 01:49 /wc/output3/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 48 2017-06-17 01:49 /wc/output3/part-r-00000
[hadoop@hadoop1 app]$ hadoop fs -cat /wc/output3/part-r-00000
abc 1
bye 1
good 1
hello 4
jack 1
tom 1
world 1
可以看到默认按照key的字符顺序列出来了
- mr本地运行模式
在windows中运行本地模式需要winutils.exe等工具和设置
并且把输入输出修改为本地路径 new Path("d:/wc/srcdata/"
对于 new Path("hdfs://hadoop1:9000/wc/output3/") 提交到集群注意权限。
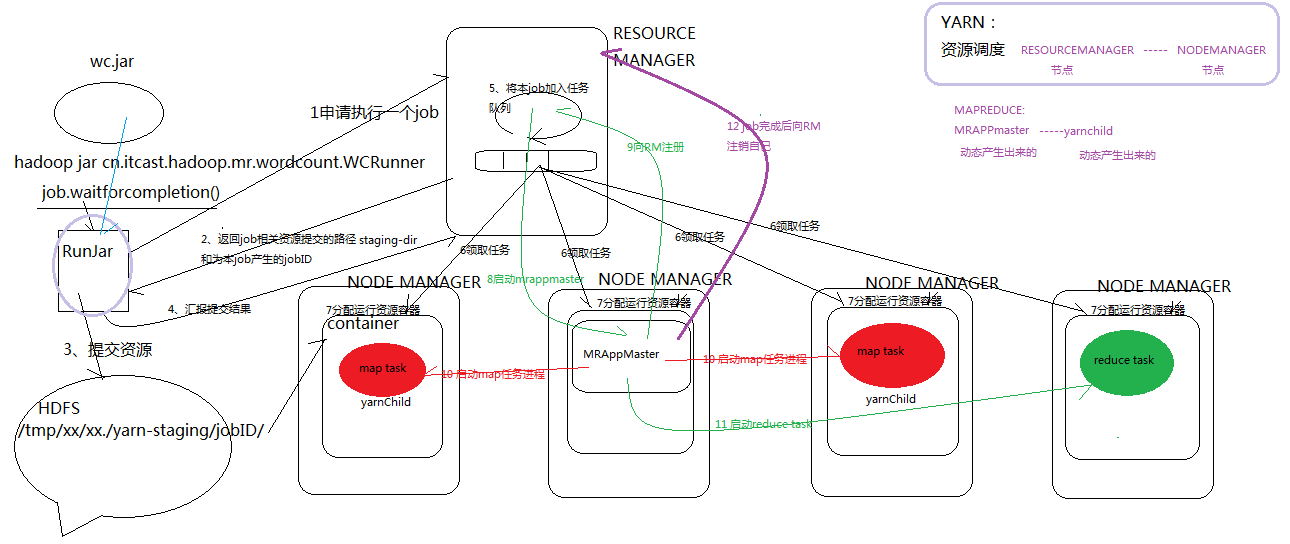
- job提交的逻辑
- mr程序的几种提交运行模式
本地模型运行
1/在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
----输入输出数据可以放在本地路径下(c:/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
2/在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
集群模式运行
1/将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner
2/在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml
----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar");
3/在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改
----要在windows中存放一份hadoop的安装包(解压好的)
----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件
----再要配置系统环境变量 HADOOP_HOME 和 PATH
----修改YarnRunner这个类的源码
- YARN的通用性意义
yarn里面不仅可以跑mapreduce,还可以运行其他的计算。
mapreduce速度特别慢,不适合实时性强的场景。因为它的数据都是放在磁盘上。
strom和spark现在很火,这两个框架适合实时计算。
而我不管这些框架怎么计算,只要符合我的yarn框架要求,都可以放在yarn里跑。
要符合yarn的要求,需要一个主管进程来管理,即app master。
你的map master要符合我yarn的要求,有一个继承我的appmaster的类。
所以yarn的出现大大扩展了hadoop的场景和生命周期。
所以hadoop有了hdfs和yarn,应用非常广。
- yarn的job提交流程
客户端通过
wcjob.waitForCompletion(true);
将任务提交到集群。
waitForCompletion() -> submit()
{
connect()
......
submitter.submitJobInternal(Job.this, cluster)
}
connect() // 里给 job 成员 cluster 赋值
{
cluster = new Cluster(getConfiguration());
}
cluster里的initalize() 里创建了一个RPC客户端
通过配置文件找到合适的provider创建rpc客户端
submitJobInternal() 里
{
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
......
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
......
copyAndConfigureFiles(job, submitJobDir); //提交了jar包
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
......
int maps = writeSplits(job, submitJobDir); //获取切片信息
......
writeConf(conf, submitJobFile); //写描述信息文件xml
}
任务提交的临时文件在/tmp/hadoop-yarn/staging/hadoop/.staging/
[hadoop@hadoop1 app]$ hadoop fs -ls /tmp/hadoop-yarn/staging
Found 2 items
drwx------ - hadoop supergroup 0 2017-05-23 23:31 /tmp/hadoop-yarn/staging/hadoop
drwxr-xr-x - hadoop supergroup 0 2017-05-23 23:31 /tmp/hadoop-yarn/staging/history
[hadoop@hadoop1 app]$ hadoop fs -ls /tmp/hadoop-yarn/staging/hadoop/
Found 1 items
drwx------ - hadoop supergroup 0 2017-06-17 01:49 /tmp/hadoop-yarn/staging/hadoop/.staging
[hadoop@hadoop1 app]$ hadoop fs -ls /tmp/hadoop-yarn/staging/hadoop/.staging/
---------------------------------------------------------------------------
第四天
1 hadoop中的序列化机制
要在hadoop的各个节点之间传输,应该遵循hadoop的序列化机制,实现hadoop想要的序列化接口。
实现Writable接口
方法 write readFields
hadoop的序列化机制不会传递对象的继承结构信息
与JDK自带的序列化机制不同
因为hadoop只需要传输数据,不需要复杂的继承结构,节省网络带宽。
public class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean>
public class FlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean>
(Mapper的输出和Reducer的输入相同)
框架每传递一组数据<1387788654,{flowbean, flowbean, flowbean, flowbean......}>调用一次我们的reduce方法
reduce中的而业务逻辑就是遍历values,然后进行累加求和再输出
2 hadoop中的自定义排序实现
排序MR默认是按key2进行排序的,如果想自定义排序规则,被排序的对象要实现WritableComparable接口,在compareTo方法中实现排序规则,然后将这个对象当做k2,即可完成排序
3 mr程序中自定义分组的实现
1.实现分区的步骤:
1.1先分析一下具体的业务逻辑,确定大概有多少个分区
1.2首先书写一个类,它要继承org.apache.hadoop.mapreduce.Partitioner这个类
1.3重写public int getPartition这个方法,根据具体逻辑,读数据库或者配置返回相同的数字
1.4在main方法中设置Partioner的类,job.setPartitionerClass(DataPartitioner.class);
1.5设置Reducer的数量,job.setNumReduceTasks(6);
2. HashPartitioner是mapreduce的默认partitioner。计算方法是
which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。
