
北京黑马程序员javaEE第19期课程视频
涉及名词
vo pojo dao po bean
mybatis01
Mybatis
是一个不完全的orm框架
对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
Mybatis让程序员只关注sql本身,而不需要去关注如连接的创建、statement的创建等操作。
Mybatis用到动态代理(有两种方式)?什么玩意
代理设计模式 定义:为其他对象提供一种代理以控制对这个对象的访问
参考:彻底理解JAVA动态代理
http://www.cnblogs.com/flyoung2008/archive/2013/08/11/3251148.html
创建数据库mybatis01,选utf8_general_ci ,导入数据
新建数据库时
字符编码 整理应该是默认
utf8_unicode_ci 比较准确,
utf8_general_ci 速度比较快。
通常情况下 utf8_general_ci的准确性就够我们用的了。
参考: phpMyAdmin中mysql的创建数据库时的编码的问题
http://blog.sina.com.cn/s/blog_6dd65c6f0100umv0.html
创建项目,添加文件夹,依赖
src test config lib
1 创建PO类
参考:java中的几种对象(PO,VO,DAO,BO,POJO)
http://www.cnblogs.com/bluestorm/archive/2012/09/26/2703234.html
PO :(persistant object ),持久对象
VO :(value object) ,值对象
DAO :(Data Access Objects) ,数据访问对象接口
BO :(Business Object),业务对象层
POJO :(Plain Old Java Objects),简单的Java对象
2 创建全局配置文件
该配置文件在后面的学习会与spring整合,由spring管理
3 需求开发 - 映射文件
创建映射文件
在全局配置文件中加载映射文件
注意:在xml配置文件中配置数据库URL时,要使用&的转义字符也就是&
mybatis默认提示需要使用log4j
在config目录下配置文件log4j.properties
User.xml
#{}:表示一个占位符
#{id}:里面的id表示输入参数的参数名称,如果该参数是简单类型,那么#{}里面的参数名称可以任意
parameterType:输入参数的java类型
resultType:输出结果的所映射的java类型(单条结果所对应的java类型)
${}:表示一个sql的连接符
${value}:里面的value表示输入参数的参数名称,如果该参数是简单类型,那么${}里面的参数名称必须是value
${}这种写法存在sql注入的风险,所以要慎用!!但是在一些场景下,必须使用${},比如排序时,动态传入排序的列名,${}会原样输出,不加解释
#{} ${} 的区别
参考: http://blog.csdn.net/jimmy609/article/details/43020143
#{} 会加引号 ${}原样输出,但是有风险
穿多个参数可以用map、pojo
pojo传参
<insert id="insertUser" parameterType="com.itheima.mybatis.po.User">
<selectKey keyProperty="id" resultType="int" order="AFTER">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO USER
(username,birthday,sex,address)
VALUES(#{username},#{birthday},#{sex},#{address})
</insert>
DAO开发方式
原始dao的开发方式
编程步骤
- 根据需求创建po类
- 编写全局配置文件
- 根据需求编写映射文件
- 加载映射文件
- 编写dao接口
- 编写dao实现类
- 编写测试代码
缺点
- 有大量的重复的模板代码
- 存在硬编码
mybatis使用Mapper代理模式 来解决上述问题
减少代码冗余,包括:selectOne里填入的statement名称,以及传入的参数
Mapper代理的开发方式
即开发mapper接口(相当于dao接口)
Mapper代理使用的是jdk的代理策略。
全局配置文件
mybatis一般二级缓存没有开启
- 概览
SqlMapConfig.xml的配置内容和顺序如下(顺序不能乱):
Properties(属性)
Settings(全局参数设置)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境信息集合)
environment(单个环境信息)
transactionManager(事物)
dataSource(数据源)
mappers(映射器)
加载的顺序
-
先加载properties中property标签声明的属性
-
再加载properties标签引入的java配置文件中的属性
-
parameterType的值会和properties的属性值发生冲突。
编程步骤
- 根据需求创建po类
User.java getter setter
- 编写全局配置文件
SqlMapConfig.xml <configuration><environments>
db.properties
- 根据需求编写映射文件
UserMapper.xml <mapper><insert>
- 加载映射文件
SqlMapConfig.xml <configuration><mappers>
- 编写mapper接口
UserMapper.java
- 编写测试代码
UserMapperTest.java
详见 mybatis教案.docx
UserMapper.java 和 UserMapper.xml 要一致
类的限定名 namespace
方法名 id
形参 parameterType
返回值 resultType
Mybatis映射文件(核心)
1 输入映射
parameterType 里有 int hashmap 等 、自定义类
简单类型
传递POJO对象
传递POJO包装对象
例子都在UserMapper.java里面
在mapper里面传入 #{user.username} 时 user 这个类对象必须在 SqlMapConfig.xml 里申明别名<typeAliases> (别名为User)否则找不到User这个类
2 输出映射
resultType 列名和映射的对象的属性名一致,无需手动映射
resultMap 对列名和属性名进行映射
1 简单输出类型
2 输出POJO单个对象和列表
例子:
public interface UserMapper {
public User findUserById(int id); //简单类型输入 POJO单个对象输出
public void insertUser(User user); //POJO对象输入 无输出
public List<User> findUserList(UserQueryVO vo); //POJO包装对象输入 POJO列表输出
}
(
看了MyBatis源码,发现对于返回泛型,如SqlSession里的:
<E> List<E> selectList(String statement, Object parameter);
最终执行在SqlSession的Executor里面,比如BaseExecutor的query()里
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
直接强转的
对于SqlSession里的:
<T> T getMapper(Class<T> type);
从knoewnMappers里获得
return mapperProxyFactory.newInstance(sqlSession);
在java.lang.reflect.Proxy里用反射创建对象,但是这个接口方法的实现是谁写入的。
参考:java通过反射实列化接口
http://blog.csdn.net/u012930316/article/details/55261266
即通过自定义的InvocationHandler来完成
在这个例子中InvocationHandler是MapperProxy<T>
里面的invoke()最终会执行
return mapperMethod.execute(sqlSession, args);
execute()里首先从
Object param = method.convertArgsToSqlCommandParam(args);
里获得参数,这是把从xml文件里解析出来的项用接口输入参数匹配上
然后调用
result = rowCountResult(sqlSession.insert(command.getName(), param));
)
3 动态SQL
通过Mybatis提供的各种动态标签实现动态拼接sql
if where foreach 标签
注意:用if进行判断是否为空时,不仅要判断null,也要判断空字符串‘’;
SQL片段
提高SQL的可重用性
定义
<sql id="select_user_where">
<if test="userExt != null">AND user=1</if>
</sql>
引用:
<where>
<include refid="select_user_where"/>
</where>
foreach标签:
<if test="idList != null and idList.size > 0">
<foreach collection="idList" item="id" open="AND id IN (" close=")" separator=",">
#{id}
</foreach>
</if>
mybatis与hibernate的区别及各自应用场景
Mybatis技术特点:
- 通过直接编写SQL语句,可以直接对SQL进行性能的优化;
- 学习门槛低,学习成本低。只要有SQL基础,就可以学习mybatis,而且很容易上手;
- 由于直接编写SQL语句,所以灵活多变,代码维护性更好。
- 不能支持数据库无关性,即数据库发生变更,要写多套代码进行支持,移植性不好。
- 需要编写结果映射。
Hibernate技术特点:
- 标准的orm框架,程序员不需要编写SQL语句。
- 具有良好的数据库无关性,即数据库发生变化的话,代码无需再次编写。
- 学习门槛高,需要对数据关系模型有良好的基础,而且在设置OR映射的时候,需要考虑好性能和对象模型的权衡。
- 程序员不能自主的去进行SQL性能优化。
Mybatis应用场景:
需求多变的互联网项目,例如电商项目。
Hibernate应用场景:
需求明确、业务固定的项目,例如OA项目、ERP项目等。
mybatis02
数据模型分析
- 明确每张表存储的信息
- 明确每张表中关键字段(主键、外键、非空)
- 明确数据库中表与表之间的外键关系
- 明确业务中表与表的关系(建立在具体的业务)
一对一映射
使用resultType来进行一对一结果映射,查询出的列的个数和映射的属性的个数要一致。而且映射的属性要存在与一个大的对象中,它是一种平铺式的映射,即数据库查询出多少条记录,则映射成多少个对象。
在一对一结果映射时,使用resultType更加简单方便,如果有特殊要求(对象嵌套对象)时,需要使用resultMap进行映射,比如:查询订单列表,然后在点击列表中的查看订单明细按钮,这个时候就需要使用resultMap进行结果映射。而resultType更适应于查询明细信息,比如,查询订单明细列表。
resultMap association
MyBatis中使用association标签来解决一对一的关联查询,association标签可用的属性如下:
- property:对象属性的名称
- javaType:对象属性的类型
- column:所对应的外键字段名称
- select:使用另一个查询封装的结果
一对多映射
resultMap collection
collection聚集
聚集元素用来处理“一对多”的关系。需要指定映射的Java实体类的属性,属性的javaType(一般为ArrayList);列表中对象的类型ofType(Java实体类);对应的数据库表的列名称;
不同情况需要告诉MyBatis 如何加载一个聚集。
多对多映射
resultMap collection association
延迟加载
resultMap中的association和collection标签具有延迟加载的功能。
延迟加载的意思是说,在关联查询时,利用延迟加载,先加载主信息。需要关联信息时再去按需加载关联信息。这样会大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
设置:
Mybatis默认是不开启延迟加载功能的,我们需要手动开启。
需要在SqlMapConfig.xml文件中,在<settings>标签中开启延迟加载功能。
lazyLoadingEnabled、aggressiveLazyLoading
使用:
- 编写映射文件
<resultMap type="cn.itcast.mybatis.po.Orders" id="OrdersUserLazyLoadingRstMap">
......
<association property="user" select="cn.itcast.mybatis.mapper.UserMapper.findUserById" column="user_id"></association>
</resultMap>
<select id="findOrdersUserLazyLoading" resultMap="OrdersUserLazyLoadingRstMap">
SELECT * FROM orders
</select>
- 加载映射文件
<package name="cn.itcast.mybatis.mapper"/>
-
编写mapper接口
public List<Orders> findOrdersUserLazyLoading();
-
编写测试代码
List<Orders> list = ordersMapper.findOrdersUserLazyLoading();
for(Orders orders : list){
System.out.println(orders.getUser());
}
N+1现象:一个sql查出来N条记录,每条记录都对应一条sql,总共N+1条sql
数据量大时对性能影响大
查询缓存
Mybatis的缓存,包括一级缓存和二级缓存
一级缓存指的就是sqlsession,在sqlsession中有一个数据区域,是map结构,这个区域就是一级缓存区域。一级缓存中的key是由sql语句、条件、statement等信息组成一个唯一值。一级缓存中的value,就是查询出的结果对象。
二级缓存指的就是同一个namespace下的mapper,二级缓存中,也有一个map结构,这个区域就是一级缓存区域。一级缓存中的key是由sql语句、条件、statement等信息组成一个唯一值。一级缓存中的value,就是查询出的结果对象。
一级缓存是默认使用的。
二级缓存需要手动开启。
如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
如果调用相同namespace下的mapper映射文件中的增删改SQL,并执行了commit操作。此时会清空该namespace下的二级缓存。
<!-- 开启二级缓存总开关 -->
<setting name="cacheEnabled" value="true"/>
<!-- 开启本mapper下的namespace的二级缓存,默认使用的是mybatis提供的PerpetualCache -->
<cache></cache>
类实现序列化Serializable
禁用二级缓存
<select id="findUserById" parameterType="int" resultType="cn.itcast.mybatis.po.User" useCache="false">
SELECT * FROM user WHERE id = #{id}
</select>
刷新二级缓存
该statement中设置flushCache=true可以刷新当前的二级缓存,默认情况下如果是select语句,那么flushCache是false。如果是insert、update、delete语句,那么flushCache是true。
整合ehcache
Mybatis本身是一个持久层框架,它不是专门的缓存框架,所以它对缓存的实现不够好,不能支持分布式。
Ehcache是一个分布式的缓存框架。
对缓存数据进行集中管理(redis集群)
使用分布式缓存框架 redis、memcached、ehcache。
互联网项目一定要做三个测试:功能测试、性能测试、安全测试。
Cache是一个接口,它的默认实现是mybatis的PerpetualCache。如果想整合mybatis的二级缓存,那么实现Cache接口即可。
整合ehcache的步骤
1 引入ehcache的jar包;
2 在mapper映射文件中,配置cache标签的type为ehcache对cache接口的实现类类型。
3 加入ehcache的配置文件
使用场景:
对于访问响应速度要求高,但是实时性不高的查询,可以采用二级缓存技术。
局限性
Mybatis二级缓存对细粒度的数据,缓存实现不好。
因为二级缓存是mapper级别的,当一个商品的信息发送更新,所有的商品信息缓存数据都会清空。
解决此类问题,需要在业务层根据需要对数据有针对性的缓存。
比如可以对经常变化的 数据操作单独放到另一个namespace的mapper中。
Mybatis整合spring
Mybatis的逆向工程(会用)
简单点说,就是通过数据库中的单表,自动生成java代码。
直接看 SpringMVC 完全看不懂啊,得去看Spring
先把前面基础看了
02_第二阶段Java web_day01 html笔记
第一阶段
文本标签 html head title body
排版标签 <!--注释--> <p> <br> <hr>
块标签 div span
字体标签 font h1~h6
列表标签 ul li ol
图形标签 img
链接标签 a
表格标签 table tr td caption th thead tbody tfoot
div与span区别
div占用的位置是一行,span占用的是内容有多宽就占用多宽的空间距离
本阶段的重点
- 超链接
- 表格
第二阶段
表单标签 form input(text password radio checkbox button hidden file submit reset image) select option textarea
post与get的区别
共同:
- 可以用来提交或请求数据
- GET、POST无法保证安全性
不同:
- GET使用URL传参。而POST将数据放在BODY中,在地址栏上不可见,不会保留在浏览器历史记录中
- GET 请求可被缓存,POST 请求不会被缓存
- GET对数据长度有限制(IE8 中URL 的最大长度是 4076 个字符)
参考:HTTP 方法:GET 对比 POST
http://www.w3school.com.cn/tags/html_ref_httpmethods.asp
重点:对于表单标签要求大家都需要掌握
第三阶段
HTML框架及特殊字符
其他标签 meta标签(属性 content http-equiv name) link标签(属性 type href rel)
特殊字符 < &ht; ® ©
框架标签 <frameset> <frame> <iframe>
02_第二阶段Java web_day02_css&js css与javascript笔记
第一阶段
CSS 指层叠样式表 (Cascading Style Sheets)
Css规则主要由两部分组成 1.选择器 2.一条或多条声明
导入CSS
- 内联样式表 <div style="border:1px solid black">这是一个DIV</div>
- 内部样式表 <style>标签在html文档的<head>中来定义
- 外部样式表 使用<link>标签来导入 @import导入
CSS选择器
- id选择器 #d {}
- 类选择器 .d {}
- 元素选择器 div {}
- 属性选择器 input [type="text/css"] {}
- 伪类 链接的不同状态都可以不同的方式显示,包括:a:active活动状态,a:visited已被访问状态,a:link未被访问状态,a:hover和鼠标悬念状态
CSS属性
- 字体 font font-family font-size font-style
- 文本 color text-align letter-spacing letter-spacing word-spacing
- 背景 background background-color background-image background-position background-repeat
- 尺寸 width height
- 列表 list-style list-style-image list-style-position list-style-type
- 表格 border-collapse border-spacing caption-side
- 轮廓 outline outline-color outline-style outline-width
- 定位 position top right left bottom
- 分类 clear float cursor display visibility
CSS框模型
盒子模型 element元素 padding内边距 margin外边距 border边框
问题:
- css基本语法是什么
Css规则主要由两部分组成 1.选择器 2.一条或多条声明
- css导入方式有几种
四种
- 外部导入与@import有什么区别
-
@import这种方式只有firefox支持,而ie不支持。
- @import这种方式导入的css,会在整个页面加载后,才会加载样式。如果网络不好情况下,会先看到无样式修饰的页面,闪烁一下后,才会看到有样式修饰的页面。 而使用外部样式表,会先装载样式表,这样看到的就是有样式修饰的页面。
-
@import不支持通过javascript修改样式,而link支持。
- Css选择器的作用是什么,并说出常见三种选择器。
css选择器主要是用于选择需要添加样式的html元素。
id选择器 类选择器 元素选择器 属性选择器 伪类
- display=none与visibility=hidden有什么区别
display:none 不为被隐藏的对象保留其物理空间 visibility:hidden 为被隐藏的对象保留其物理空间,visibility就会在加载页面的同时就已经把它加载进来了
第二阶段
HTML+CSS案例
第三阶段
JavaScript 是因特网上最流行的脚本语言,它存在于全世界所有 Web 浏览器中,能够增强用户与 Web 站点和 Web 应用程序之间的交互。
javascript作用:我们通过javascript可以改变html内容,改变html样式,进行验证输入等。
javascript的核心ECMAScript描述了语言的语法和基本对象。
一个完整的javaScript实现是由下面三个不同部分组成的。
核心ECMAScript 文档对象模型DOM 浏览器对象模型BOM
导入js的方式
- 在html页面中直接插入javascript <script>
- 引入外部的javascript <script src="xxx.js"></script>
Javascript基础语法
- 变量声明 var 大小写敏感
- 数据类型 原始类型(String Number Boolean Undefined Null) 引用类型(var ojb = new Object()) typeof instanceof
- 类型转换 toString() parseInt() parseFloat() 强制类型转换
- 运算符与表达式 一元运算符(++ -- void) 逻辑运算符(NOT AND OR) 加性运算符(+) 关系运算符(> >= < <=) 等性运算符(== === != !===) 三元运算符( > ? ) 赋值运算符(=) 逗号运算符(var a=1,b=2,c=3)
- 条件语句 if switch
- 循环语句 for while do-while
问题:
Javascript中2==”2”与2===”2”的结果是什么,为什么?
true false
全等号由三个等号表示(===),只有在无需类型转换运算数就相等的情况下,才返回true。
JS中的NaN、undefined、null
http://blog.csdn.net/limm33/article/details/50955852
NaN 就是除过数字的任意值
javascript中的void运算符语法及使用介绍
http://www.jb51.net/article/34651.htm
javascript:void(表达式)
javascript:void 表达式
void会计算表达式的值,但是会丢弃表达式的返回值。
重点:
Javascript中的数据类型
Javascript中的运算符
Javascript中的控制语句
总结:
对于css我们只需要掌握其基本语法结构与选择器,其它的做为了解,在开发中可以看懂css代码,并完成简单的修改就可以。
Javascript在现在的web开发中应用越来越多,对于javascript希望大家回以重视,希望大家可以将所有的javascript内容掌握。
02_第二阶段Java web_day03_第03天javascript笔记
第一阶段:
javascript常用对象
- Boolean
new Boolean(value);//构造函数 Boolean(value);//转换函数,返回原始布尔值 省略 value 参数,或者设置为 0、-0、null、""、false、undefined 或 NaN 为false
-
Number
new Number(value);构造 Number(value);转换函数 如果转换失败,则返回 NaN
-
Array
new Array(size);new Array(element0, element1, ..., elementn); 方法:concat join pop 等
-
String
一种基本的数据类型 new String(s); String(s); JavaScript 的字符串是不可变的(immutable)
-
Date
Date 对象用于处理日期和时间 方法:getDate(天:1~31) getYear (年:0~6) setDate() 等
-
Math
用于执行数学任务 如:Math.sqrt(15);
-
RegExp
表示正则表达式,它是对字符串执行模式匹配的强大工具
重点:
数组的创建与常用方法
String中常用方法
Javascript中正则的使用
第二阶段:
javascript函数与事件
Javascript函数创建与使用
三种创建方式
- function 函数名称(参数列表){ 函数体; }
- var 函数名称=function(参数列表){ 函数体; }
- Var 函数名称=new Function(参数列表,函数体);
只要求掌握第一种与第二种,对于第三种大家了解就可以
函数调用时传递的参数不一定要与函数声明时的参数个数一致
在javascript中有一个特殊的对象arguments,我们可以通过它来获取所有函数中的参数。
Javascript全局函数介绍
decodeURI() 解码某个编码的 URI。
decodeURIComponent() 解码一个编码的 URI 组件。
encodeURI() 把字符串编码为 URI。
encodeURIComponent() 把字符串编码为 URI 组件。
escape() 对字符串进行编码。
eval() 计算 JavaScript 字符串,并把它作为脚本代码来执行。
getClass() 返回一个 JavaObject 的 JavaClass。
isFinite() 检查某个值是否为有穷大的数。
isNaN() 检查某个值是否是数字。
Number() 把对象的值转换为数字。
parseFloat() 解析一个字符串并返回一个浮点数。
parseInt() 解析一个字符串并返回一个整数。
String() 把对象的值转换为字符串。
unescape() 对由 escape() 编码的字符串进行解码。
Javascript事件介绍
事件通常与函数配合使用,这样我们可以通过发生的事件来驱动函数执行.
onabort 图像加载被终端
onclick 鼠标点击某个对象
......
事件绑定
-
html事件属性
<button onclick="displayDate()">点击这里</button>
-
html dom分配事件
<script>
document.getElementById("myBtn").onclick=function(){displayDate()};
</script>
阻止默认事件
if(e&&e.stopPropagation){
e.preventDefault();
}else{
window.event.returnValue = false;
}
阻止事件传播
if(e&&e.stopPropagation){
e.stopPropagation();
}else{
window.event.cancelBubble = true;
}
题目:
Javascipt中怎样创建函数
Javascript中怎样获取函数的参数列表
Javascript中的eval函数有什么作用
例举出javascript中五种常用事件
Javascript中怎样完成事件的注册(绑定)
重点:
函数创建
全局函数使用
事件的使用
第三阶段
javascript BOM与DOM介绍
BOM(浏览器对象模型)
由于没有相关的 BOM 标准,每种浏览器都有自己的 BOM 实现。有一些事实上的标准,如具有一个窗口对象和一个导航对象。
Window对象
Window 对象表示浏览器中打开的窗口
History对象
History 对象包含用户(在浏览器窗口中)访问过的 URL。
History 对象是 window 对象的一部分,可通过 window.history 属性对其进行访问。
Location对象
Location 对象包含有关当前 URL 的信息。可通过 window.location 属性来访问。
DOM(文档对象模型)是 HTML 和 XML 的应用程序接口(API)。DOM 将把整个页面规划成由节点层级构成的文档。
W3C DOM 标准被分为 3 个不同的部分:
- 核心 DOM - 针对任何结构化文档的标准模型
- XML DOM - 针对 XML 文档的标准模型
- HTML DOM - 针对 HTML 文档的标准模型
在XML DOM每个元素 都会被解析为一个节点Node,而常用的节点类型又分为
元素节点 Element
属性节点 Attr
文本节点 Text
文档节点 Document
题目:
简单说一下什么是javascript的dom与bom对象
常用的bom对象有哪些
重点:
Window,History,Location对象的使用
DOM的简单操作
第四阶段
javascript案例-注册表单校验
问答题:
Javascript创建函数有几种方式
Javascript中函数调用与java中有什么区别
Javascript中函数是否有参数与返回值,与java中有什么区别
Javascript中函数创建有
javascript中怎样完成事件的绑定
例举出javascript中常见的五种事件
什么是dom,它有什么作用
setInterval()与setTimeout有什么区别?
Xml中的节点有几种
Dom操作中获取节点方式有几种
02_第二阶段Java web ★★ day04 ★ 0201_SQL入门
SQL入门
- SQL简介
- 常用数据库
- MySQL安装与配置
- DDL数据定义语言
- DML数据操纵语言
- DQL数据查询语言(简单)
- 数据完整性
- 多表设计
- DQL数据查询语言(复杂查询:连接查询 子查询 联合查询 报表查询)
- 数据库的备份与恢复
数据库(DataBase,DB):指长期保存在计算机的存储设备上,按照一定规则组织起来,可以被各种用户或应用共享的数据集合。
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中的数据。
SQL:Structure Query Language。
SQL被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准,后来被国际化标准组织(ISO)采纳为关系数据库语言的国际标准。
DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
DML(Data Manipulation Language):数据操作语言,用来操作数据库表中的记录(数据);
DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
4 DDL 数据定义语言 CREATE ALTER DROP
创建数据库
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name //指定字符集
| [DEFAULT] COLLATE collation_name //指定数据库字符集的比较方式
查看、删除数据库
显示数据库语句:
SHOW DATABASES
显示数据库创建语句:
SHOW CREATE DATABASE db_name
数据库删除语句:
DROP DATABASE [IF EXISTS] db_name
修改、备份、恢复数据库
ALTER DATABASE [IF NOT EXISTS] db_name [alter_specification[, alter_specification] ...]
alter_specification:
[DEFAULT] CHARACTER SET charset_name
| [DEFAULT] COLLATE collation_name
创建表(基本语句)
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校对规则
field:指定列名 datatype:指定列类型
修改表
ALTER TABLE table_name
ADD (column datatype [DEFAULT expr] [, column datatype]...);
ALTER TABLE table_name
MODIFY column datatype [DEFAULT expr] [, column datatype]...;
修改表的名称:Rename table表名 to 新表名
修改表的字符集:alter table student character set utf8;
5 DML数据操纵语言 INSERT UPDATE DELETE
向表中插入数据
INSERT INTO table [(column [, column...])]
VALUES (value [, value...]);
Tip:mysql中文乱码
lmysql有六处使用了字符集,分别为:client 、connection、database、results、server 、system。
修改表中数据
UPDATE tbl_name
SET col_name1=expr1[, col_name2=expr2...]
[WHERE where_definition]
删除表中数据
delete from _name
[WHERE where_definition]
6 DQL数据查询语言(简单的) SELECT
SELECT [DISTINCT] *|{column1, column2, column3..}
FROM table;
DISTINCT可选,指显示结果时,是否剔除重复数据
在select语句中可使用表达式对查询的列进行运算
SELECT *|{column1|expression, column2|expression,..}
FROM table;
在select语句中可使用as语句
SELECT column as 别名 from 表名;
where子句里的运算符
> < >= <= = <>
BETWEEN AND
IN(set)
LIKE 'pattern'
IS NULL
and
or
not
使用order by 子句排序查询结果
SELECT column1, column2. column3..
FROM table;
order by column asc|desc
7 数据完整性
数据完整性是为了保证插入到数据中的数据是正确的,它防止了用户可能的输入错误。
- 实体完整性 表的一行(即每一条记录)在表中是唯一的实体。通过主键实现。
- 域完整性 数据库表的列(即字段)必须符合某种特定的数据类型或约束。比如NOT NULL。
- 参照完整性 保证一个表的外键和另一个表的主键对应。
定义表的约束
定义主键约束
primary key:不允许为空,不允许重复
删除主键:alter table tablename drop primary key ;
定义主键自动增长 auto_increment
定义唯一约束 unique
定义非空约束 not null
定义外键约束 constraint ordersid_FK foreign key(ordersid) references orders(id),
8 多表设计
一对多
多对多
一对一
9 DQL数据查询语言(复杂的)
连接查询:
•交叉连接(cross join):不带on子句,返回连接表中所有数据行的笛卡儿积。
•内连接(inner join):返回连接表中符合连接条件及查询条件的数据行。
•外连接:分为左外连接(left out join)、右外连接(right outer join)。与内连接不同的是,外连接不仅返回连接表中符合连接条件及查询条件的数据行,也返回左表(左外连接时)或右表(右外连接时)中仅符合查询条件但不符合连接条件的数据行。
子查询
联合查询
报表查询
连接查询的from子句的连接语法格式为:
from TABLE1 join_type TABLE2 [on (join_condition)] [where (query_condition)]
交叉连接查询CUSTOMER表和ORDERS表
SELECT * FROM customer CROSS JOIN orders;
SELECT * FROM customer,orders;
内连接
显式内连接:使用inner join关键字,在on子句中设定连接条件
SELECT * FROM customer c INNER JOIN orders o ON c.id=o.customer_id;
隐式内连接:不包含inner join关键字和on关键字,在where子句中设定连接条件
SELECT * FROM customer c,orders o WHERE c.id=o.customer_id;
右外连接查询
使用right outer join关键字,在on子句中设定连接条件
SELECT * FROM customer c RIGHT OUTER JOIN orders o ON c.id=o.customer_id;
子查询也叫嵌套查询,是指在select子句或者where子句中又嵌入select查询语句,子查询的语句放在小括号之内。
查询“陈冠希”的所有订单信息
SELECT * FROM orders WHERE customer_id=(SELECT id FROM customer WHERE name LIKE '%陈冠希%');
左外连接查询
使用left outer join关键字,在on子句中设定连接条件
SELECT * FROM customer c LEFT OUTER JOIN orders o ON c.id=o.customer_id;
不仅包含符合c.id=o.customer_id连接条件的数据行,还包含customer左表中的其他数据行
联合查询
联合查询能够合并两条查询语句的查询结果,去掉其中的重复数据行,然后返回没有重复数据行的查询结果。联合查询使用union关键字
SELECT * FROM orders WHERE price>200 UNION SELECT * FROM orders WHERE customer_id=1;
报表查询
报表查询对数据行进行分组统计,其语法格式为:
[select …] from … [where…] [ group by … [having… ]] [ order by … ]
其中group by 子句指定按照哪些字段分组,having子句设定分组查询条件。在报表查询中可以使用SQL函数。
合计函数-count
Count(列名)返回某一列,行的总数
Select count(*)|count(列名) from tablename [WHERE where_definition]
合计函数-SUM
Sum函数返回满足where条件的行的和
Select sum(列名){,sum(列名)…} from tablename [WHERE where_definition]
合计函数-AVG
AVG函数返回满足where条件的一列的平均值
Select avg(列名){,avg(列名)…} from tablename [WHERE where_definition]
合计函数-MAX/MIN
Max/min函数返回满足where条件的一列的最大/最小值
Select max(列名) from tablename [WHERE where_definition]
Having和where均可实现过滤,但在having可以使用合计函数,having通常跟在group by后,它作用于组。
时间日期相关函数
示例:
select addtime(‘02:30:30’,‘01:01:01’); 注意:字符串、时间日期的引号问题
select date_add(entry_date,INTERVAL 2 year) from student;//增加两年
select addtime(time,‘1 1-1 10:09:09’) from student; //时间戳上增加,注意年后没有-
字符串相关函数
数学相关函数
10 数据的备份与恢复
数据库备份:
mysqldump -u root -psorry test>test.sql
数据库恢复:
•创建数据库并选择该数据库
•SOURCE 数据库文件
•或者:
•mysql -u root -psorry test<test.sql
02_第二阶段Java web ★★ day06 ★ jdbc笔记
一、JDBC概述
JDBC:java database connectivity SUN公司提供的一套操作数据库的标准规范。
JDBC与数据库驱动的关系:接口与实现的关系。
JDBC规范(掌握四个核心对象):
DriverManager:用于注册驱动
Connection: 表示与数据库创建的连接
Statement: 操作数据库sql语句的对象
ResultSet: 结果集或一张虚拟表
二、开发一个JDBC程序
1、创建数据库表,并向表中添加测试数据
2、创建java project项目,添加数据库驱动(*.jar)
3、实现JDBC操作
//1、注册驱动
//2、创建连接
//3、得到执行sql语句的Statement对象
//4、执行sql语句,并返回结果
//5、处理结果
//6关闭资源
三、JDBC常用的类和接口详解
a、注册驱动
DriverManager.registerDriver(new com.mysql.jdbc.Driver());不建议使用
原因有2个:
> 导致驱动被注册2次。
> 强烈依赖数据库的驱动jar
解决办法:
Class.forName("com.mysql.jdbc.Driver");
DriverManager.registerDriver和 Class.forName()的异同
http://blog.csdn.net/hjf19790118/article/details/6857012
在 com.mysql.jdbc.Driver中有一段静态代码块,是向 DriverManager注册一个Driver实例。这样在Class.forName("com.mysql.jdbc.Driver")的时候,就会首先去执行这个静态代码块,于是和DriverManager.registerDriver(new Driver())有了相同的效果。
四、使用JDBC实现CRUD操作
CRUD
增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)
五、实现一个用户登录的功能
六、SQL注入问题:preparedStatement
preparedStatement:预编译对象, 是Statement对象的子类。
02_第二阶段Java web ★★ day07 ★ 01、XML笔记
XML:eXtensible Markup Language 可扩展标记语言 version="1.0"
* 可扩展:所有的标签都是自定义的。
* 功能:数据存储
* 配置文件
* 数据传输
* html与xml区别:
* html语法松散,xml语法严格
* html做页面展示,xml做数据存储
* html所有标签都是预定义的,xml所有标签都是自定义的
W3C:word wide web consortiem 万维网联盟
xml语法:
* 文档声明:
* 必须写在xml文档的第一行。
* 写法:<?xml version="1.0" ?>
* 属性:
* version:版本号 固定值 1.0
* encoding:指定文档的码表。默认值为 iso-8859-1
* standalone:指定文档是否独立 yes 或 no
* 元素:xml文档中的标签
** 文档中必须有且只能有一个根元素
* 元素需要正确闭合。<body></body> <br/>
* 元素需要正确嵌套
* 元素名称要遵守:
* 元素名称区分大小写
* 数字不能开头
* 文本:
* 转义字符:>
* CDATA: 里边的数据会原样显示
* <![CDATA[ 数据内容 ]]>
* 属性:
* 属性值必须用引号引起来。单双引号都行
* 注释:
<!-- -->
* 处理指令:现在基本不用
<?xml-stylesheet type="text/css" href="1.css"?>
xml约束:
* 约束就是xml的书写规则
* 约束的分类:
dtd:
dtd分类:
* 内部dtd:在xml内部定义dtd
* 外部dtd:在外部文件中定义dtd
* 本地dtd文件:<!DOCTYPE students SYSTEM "student.dtd">
* 网络dtd文件:<!DOCTYPE students PUBLIC "名称空间" "student.dtd">
schema:
导入xsd约束文档:
1、编写根标签
2、引入实例名称空间 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3、引入名称空间 xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4、引入默认的名称空间
XML解析:
* 解析xml可以做:
* 如果xml作为配置文件:读取
* 如果xml作为传输文件:写,读
* xml解析思想:
* DOM:将文档加载进内存,形成一颗dom树(document对象),将文档的各个组成部分封装为一些对象。
* 优点:因为,在内存中会形成dom树,可以对dom树进行增删改查。
* 缺点:dom树非常占内存,解析速度慢。
Document
Element
Text
Attribute
Comment
* SAX:逐行读取,基于事件驱动
* 优点:不占内存,速度快
* 缺点:只能读取,不能回写
* xml常用的解析器:
* JAXP:sun公司提供的解析。支持dom和sax。
* JDOM:
* DOM4J:dom for java民间方式,但是是事实方式。非常好。 支持dom
1.导入jar包 dom4j.jar
2.创建解析器
SAXReader reader = new SAXReader();
3.解析xml 获得document对象
Document document = reader.read(url);
* XPATH:专门用于查询
* 定义了一种规则。
* 使用的方法:
* selectSingleNode():
* selectNodes():
使用步骤:
1、注意:要导包 jaxen...jar
2、创建解析器
SAXReader reader = new SAXReader();
3、解析xml 获得document对象
Document document = reader.read(url);
---------------------------------------------------------------------------
02_第二阶段Java web ★★ day07 ★ Tomcat服务器&http笔记
javaSE:
javaEE:13种
javaME:
JavaEE规范: 13种技术的总称。Servlet/Jsp JDBC JNDI JTA...
Tomcat:Servlet/Jsp容器,轻量级服务器。
Tomcat的主要目录:(重要)
bin conf lib logs temp webapps work
标准的JavaWeb应用的目录结构(很重要:记住)
应用:
MyApp
1.html
Css
myStyle.css
Js
My.js
WEB-INF : 注意:固定写法。此目录下的文件不能被外部直接访问。
classes: 我们编写的程序代码。.class文件
lib : 应用需要用的jar文件
web.xml : 应用的配置信息
URL: 统一资源定位符(网址)
URI: 统一资源标识符
http://localhost:8080/day08_02/1.html
协议 主机IP(端口号) URI(当前应用的资源路径)
HTTP协议概述
HTTP是HyperText Transfer Protocol(超文本传输协议)的简写,传输HTML文件。
用于定义WEB浏览器与WEB服务器之间交换数据的过程及数据本身的格式。
请求部分
- 请求消息行
- 请求消息头
- 消息正文
响应部分
- 响应消息行
- 响应消息头
- 响应正文
响应状态码:
常用的就40多个。
200(正常) 一切正常
302/307(临时重定向)
304(未修改)
表示客户机缓存的版本是最新的,客户机可以继续使用它,无需到服务器请求。
404(找不到) 服务器上不存在客户机所请求的资源。
500(服务器内部错误)
02_第二阶段Java web ★★ day08 ★ Servlet笔记
servlet 是运行在 Web 服务器中的小型 Java 程序(即:服务器端的小应用程序)。servlet 通常通过 HTTP(超文本传输协议)接收和响应来自 Web 客户端的请求。
Servlet生命周期(重要)
实例化-->初始化-->服务->销毁
出生:(实例化-->初始化)第一次访问Servlet就出生(默认情况下)
活着:(服务)应用活着,servlet就活着
死亡:(销毁)应用卸载了servlet就销毁。
Servlet的三种创建方式
4.1、实现javax.servlet.Servlet接口(参见:编写一个servlet程序:)
4.2、继承javax.servet.GenericServlet类(适配器模式)
4.3、继承javax.servlet.http.HttpServlet类(模板方法设计模式)
单实例:每次访问多线程
解决线程安全问题的最佳办法,不要写全局变量,而写局部变量。
Servlet获取配置信息
ServletConfig的使用
作用1:可以获取servlet配置信息
作用2:可以获得ServletContext对象
ServletContext(重要)
ServletContext: 代表的是整个应用。一个应用只有一个ServletContext对象。单实例。
作用:
域对象:在一定范围内(当前应用),使多个Servlet共享数据。
常用方法:
void setAttribute(String name,object value);//向ServletContext对象的map中添加数据
Object getAttribute(String name);//从ServletContext对象的map中取数据
void rmoveAttribute(String name);//根据name去移除数据
获取全局配置信息:
String getInitParameter(String name) //根据配置文件中的key得到value
获取资源路径:
String getRealPath(String path);//根据资源名称得到资源的绝对路径
实现Servlet的转发:
RequestDispatcher getRequestDispatcher(String path) ;//参数表示要跳转到哪去
---------------------------------------------------------------------------
02_第二阶段Java web ★★ day09 ★ Request&Response
Web服务器收到客户端的http请求,会针对每一次请求,分别创建一个用于代表请求的request对象、和代表响应的response对象。
request和response对象即然代表请求和响应,那我们要获取客户机提交过来的数据,只需要找request对象就行了。要向容器输出数据,只需要找response对象就行了。
HttpServletResponse
HttpServletResponse对象代表服务器的响应。这个对象中封装了向客户端发送数据、发送响应头,发送响应状态码的方法。
response常见应用
- 向客户端输出中文数据
response.getOutputStream().write("中国".getBytes("UTF-8"));//以UTF-8编码发送数据,浏览器(默认用GB2312)会出现乱码
解决办法:
2.1通过更改浏览器的编码方式:IE/”查看”/”编码”/”UTF-8”(不可取)
2.2通过设置响应头告知客户端编码方式:response.setHeader(“Content-type”, “text/html;charset=UTF-8”);//告知浏览器数据类型及编码
2.3通过meta标签模拟请求头:out.write("<meta http-equiv='Content-Type' content='text/html; charset=utf-8' />".getBytes());
2.4通过以下方法:response.setContentType("text/html;charset=UTF-8");
总结:程序以什么编码输出,就需要告知客户端以什么编码显示。
用PrintWriter(字符流)发送数据:
示例:response.getWriter().write(“中国” );
- 文件下载
- 输出随机图片(CAPTCHA图像):Completely Automated Public Turing Test to Tell Computers and Humans Apart (全自动区分计算机和人类的测试)
- 发送http头,控制浏览器定时刷新网页
- 发送http头,控制浏览器缓存当前文档内容
response.setDateHeader(“Expires”, System.currentTimeMillis()+1000*60*60);//缓存1小时,注意此处是相对于1970年1月1日00:00:00的时间
- 通过response实现请求重定向。
实现方式
–response.sendRedirect()
–实现原理:
302/307状态码和location头即可实现重定向
HttpServletRequest
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过这个对象的方法,可以获得客户这些信息。
Request常用方法
•获得客户机信息
–getRequestURL方法返回客户端发出请求时的完整URL。
–getRequestURI方法返回请求行中的资源名部分。
–getQueryString 方法返回请求行中的参数部分。
–getRemoteAddr方法返回发出请求的客户机的IP地址
–getRemoteHost方法返回发出请求的客户机的完整主机名
–getRemotePort方法返回客户机所使用的网络端口号
–getLocalAddr方法返回WEB服务器的IP地址。
–getLocalName方法返回WEB服务器的主机名
–getMethod得到客户机请求方式
•获得客户机请求头
–getHead(name)方法
–getHeaders(String name)方法
–getHeaderNames方法
•获得客户机请求参数(客户端提交的数据)
–getParameter(name)方法
–getParameterValues(String name)方法
–getParameterNames方法
–getParameterMap方法 //做框架用,非常实用
–getInputStream
request常见应用1
•各种表单输入项数据的获取
–text、password、radio、checkbox、
–file、select、textarea、 hidden、
–image、button给js编程用
•请求参数的中文乱码问题
–浏览器是什么编码就以什么编码传送数据
–解决:request.setCharacterEncoding(“UTF-8”);//POST有效
–newString(username.getBytes(“ISO-8859-1”),“UTF-8”);//GET方式
–超链接:<a href=“/JavaWeb/RequestDemo2?name=中国”>cn</a>//GET方式
–更改Tomcat的配置解决URL编码问题:<Connector URIEncoding=“UTF-8”/>
request常见应用2
•request对象实现请求转发:请求转发指一个web资源收到客户端请求后,通知服务器去调用另外一个web资源进行处理。
•request对象提供了一个getRequestDispatcher方法,该方法返回一个RequestDispatcher对象,调用这个对象的forward方法可以实现请求转发。
•request对象同时也是一个域对象,开发人员通过request对象在实现转发时,把数据通过request对象带给其它web资源处理。
setAttribute方法
getAttribute方法
removeAttribute方法
getAttributeNames方法
转发和包含
•一个Servlet对象无法获得另一个Servelt对象的引用;如果需要多个Servet组件共同协作(数据传递),只能使用Servelt规范为我们提供的两种方式:
–请求转发:Servlet(源组件)先对客户请求做一些预处理操作,然后把请求转发给其他web组件(目标组件)来完成包括生成响应结果在内的后续操作。
–包含:Servelt(源组件)把其他web组件(目标组件)生成的响应结果包含到自身的响应结果中。
•转发和请求的共同点
–源组件和目标组件处理的都是同一个客户请求,源组件和目标组件共享同一个ServeltRequest和ServletResponse对象
–目标组件都可以为Servlet、JSP或HTML文档
–都依赖 javax.servlet.RequestDispatcher接口
RequestDispather
•表示请求分发器,它有两个方法:
–forward():把请求转发给目标组件
–public void forward(ServletRequest request,ServletResponse response)
– throws ServletException,java.io.IOException
–include():包含目标组件的响应结果
–public void include(ServletRequest request,ServletResponse response)
– throws ServletException,java.io.IOException
•得到RequestDispatcher对象
–1、ServletContext对象的getRequestDispather(String path1)
–path1必须用绝对路径,即以”/”开头,若用相对路径会抛出异常IllegalArgumentException
–2、ServletRequest对象的getRequestDispatcher(String path2)
–path2可以用绝对路径也可以用相对路径
转发
•dispatcher.forward(request,response)的处理流程:
•1、清空用于存放响应正文数据的缓冲区
•2、如果目标组件为Servlet或JSP,就调用它们,把它们产生的响应结果发送到客户端;如果目标组件为文件系统中的静态HTML文档,就读取文档中的数据并把它发送给客户端。
•特点:
•1、由于forward()方法先清空用于存放响应正文数据的缓冲区,因此源组件生成的响应结果不会被发送到客户端,只有目标组件生成的响应结果才会被送到客户端。
•2、如果源组件在进行请求转发之前,已经提交了响应结果(如调用了response的flush或close方法),那么forward()方法会抛出IllegalStateException。为了避免该异常,不应该在源组件中提交响应结果。
包含
•include()方法的处理流程:
•1、如果目标组件为Servlet或JSP,就执行它们,并把它们产生的响应正文添加到源组件的响应结果中;如果目标组件为HTML文档,就直接把文档的内容添加到源组件的响应结果中。
•2、返回到源组件的服务方法中,继续执行后续代码块。
•特点:
•1、源组件与被包含的目标组件的输出数据都会被添加到响应结果中。
•2、在目标组件中对响应状态代码或者响应头所做的修改都会被忽略。
请求范围
•web应用范围内的共享数据作为ServeltContext对象的属性而存在(setAttribute),只要共享ServletContext对象也就共享了其数据。
•请求范围内的共享数据作为ServletRequest对象的属性而存在(setAttribute),只要共享ServletRequest对象也就共享了其数据。
重定向
•重定向机制的运作流程
•1、用户在浏览器端输入特定URL,请求访问服务器端的某个组件
•2、服务器端的组件返回一个状态码为302的响应结果。
•3、当浏览器端接收到这种响应结果后,再立即自动请求访问另一个web组件
•4、浏览器端接收到来自另一个web组件的响应结果。
•HttpServeltResponse的sendRedirect(String location)用于重定向
•特点
•Servlet源组件生成的响应结果不会被发送到客户端。response.sendRedirect(String location)方法一律返回状态码为302的响应结果。
•如果源组件在进行重定向之前,已经提交了响应结果,会抛出IllegalStateException。为了避免异常,不应该在源组件中提交响应结果。
•在Servlet源组件重定向语句后面的代码也会执行。
•源组件和目标组件不共享同一个ServletRequest对象。
•对于sendRedirect(String location)方法的参数,如果以“/”开头,表示相对于当前服务器根路径的URL。以“http"//”开头,表示一个完整路径。
•目标组件不必是同一服务器上的同一个web应用的组件,它可以是任意一个有效网页。
----------------------------------------------------------------------------------------
02_第二阶段Java web ★★ day10 ★ 会话管理
会话可简单理解为:用户开一个浏览器,点击多个超链接,访问服务器多个web资源,然后关闭浏览器,整个过程称之为一个会话。
保存会话数据的两种技术
•Cookie
–Cookie是客户端技术,程序把每个用户的数据以cookie的形式写给用户各自的浏览器。当用户使用浏览器再去访问服务器中的web资源时,就会带着各自的数据去。这样,web资源处理的就是用户各自的数据了。
•HttpSession
–Session是服务器端技术,利用这个技术,服务器在运行时可以为每一个用户的浏览器创建一个其独享的HttpSession对象,由于session为用户浏览器独享,所以用户在访问服务器的web资源时,可以把各自的数据放在各自的session中,当用户再去访问服务器中的其它web资源时,其它web资源再从用户各自的session中取出数据为用户服务。
Cookie API
•javax.servlet.http.Cookie类用于创建一个Cookie,response接口中定义了一个addCookie方法,它用于在其响应头中增加一个相应的Set-Cookie头字段。 同样,request接口中也定义了一个getCookies方法,它用于获取客户端提交的Cookie。Cookie类的方法:
public Cookie(String name,String value)
setValue与getValue方法
setMaxAge与getMaxAge方法 (秒)
setPath与getPath方法
setDomain与getDomain方法
getName方法
Cookie细节
•一个Cookie只能标识一种信息,它至少含有一个标识该信息的名称(NAME)和设置值(VALUE)。
•一个WEB站点可以给一个WEB浏览器发送多个Cookie,一个WEB浏览器也可以存储多个WEB站点提供的Cookie。
•浏览器一般只允许存放300个Cookie,每个站点最多存放20个Cookie,每个Cookie的大小限制为4KB。
•如果创建了一个cookie,并将他发送到浏览器,默认情况下它是一个会话级别的cookie(即存储在浏览器的内存中),用户退出浏览器之后即被删除。若希望浏览器将该cookie存储在磁盘上,则需要使用maxAge,并给出一个以秒为单位的时间。将最大时效设为0则是命令浏览器删除该cookie。
•注意,删除cookie时,path必须一致,否则不会删除
Cookie应用
记住用户名
显示用户上次浏览过的商品
HttpSession
•在WEB开发中,服务器可以为每个用户浏览器创建一个会话对象(session对象),注意:一个浏览器独占一个session对象(默认情况下)。因此,在需要保存用户数据时,服务器程序可以把用户数据写到用户浏览器独占的session中,当用户使用浏览器访问其它程序时,其它程序可以从用户的session中取出该用户的数据,为用户服务。
•Session和Cookie的主要区别在于:
– Cookie是把用户的数据写给用户的浏览器。
•Session技术把用户的数据写到用户独占的session中。
•Session对象由服务器创建,开发人员可以调用request对象的getSession方法得到session对象。
(大多数的应用都是用 Cookie 来实现Session跟踪的,还可以用URL)
Session小实验:使用IE访问某一个servlet,其它IE可以取到这个servlet存的数据吗?
(拿到该IE中保存的cookie,使用它的cookie就可以)
session实现原理
疑问:服务器是如何实现一个session为一个用户浏览器服务的?
(通过读取浏览器发送的cookie值,如cookie:Jsessionid=111,就可以识别该浏览器,从而取出对应的session)
问题:如何实现多个IE浏览器共享同一session?(应用:关掉IE后,再开IE,上次购买的商品还在。)
(设置相同的cookie键值)
session案例
使用Session完成简单的购物功能
使用Session完成用户登陆;利用Session实现一次性验证码
session案例一次性校验码
•一次性验证码的主要目的就是为了限制人们利用工具软件来暴力猜测密码。
•服务器程序接收到表单数据后,首先判断用户是否填写了正确的验证码,只有该验证码与服务器端保存的验证码匹配时,服务器程序才开始正常的表单处理流程。
•密码猜测工具要逐一尝试每个密码的前题条件是先输入正确的验证码,而验证码是一次性有效的,这样基本上就阻断了密码猜测工具的自动地处理过程。
IE禁用Cookie后的session处理
•实验演示禁用Cookie后servlet共享数据导致的问题。
•解决方案:URL重写
–response. encodeRedirectURL(java.lang.String url)
•用于对sendRedirect方法后的url地址进行重写。
–response. encodeURL(java.lang.String url)
•用于对表单action和超链接的url地址进行重写
•附加:
–Session的失效 invalidate()立刻实效
–Web.xml文件配置session失效时间
(
都对url附加上jsessionid参数进行了处理,如果需要,则在url的path后面附加上;jsessionid=xxx;如果不需要则直接返回传入的url。
encodeURL在附加jsessionid之前还对url做了判断处理:如果url为空字符串(长度为0的字符串),则将url转换为完整的URL(http或https开头的);如果url是完整的URL,但不含任何路径(即只包含协议、主机名、端口,例如http://127.0.0.1),则在末尾加上根路径符号/。
也就是encodeURL如果进行了编码,则返回的URL一定是完整URL而不是相对路径;而encodeRedirectURL则不对URL本身进行处理,只专注于添加jsessionid参数(如果需要)。
)
------------------------------------------------------------------------------------------------
02_第二阶段Java web ★★ day11 ★ JSP笔记
一、jsp概述
JSP全称是Java Server Pages,它和servle技术一样,都是SUN公司定义的一种用于开发动态web资源的技术。JSP实际上就是Servlet。
jsp = html + java
html:静态内容
servlet:服务器端的小应用程序。适合编写java逻辑代码,如果编写网页内容--苦逼。
jsp:适合编写输出动态内容,但不适合编写java逻辑。
二、jsp的原理
服务器会:
1.jsp -> 翻译为 _1_jsp.java -> 编译为 _1_jsp.class
三、jsp的最佳实践
Servlet:控制器。重点编写java代码逻辑 (获取表单数据、处理业务逻辑、分发转向)
JSP:代码显示模板。重点在于显示数据
四、jsp的基本语法
1、JSP模版元素
网页的静态内容。如:html标签和文本。
2、JSP的脚本
2.1、小脚本 <% java代码 %>
2.1、表达式 <%= 2+3 %> 等价于out.print(2+3); JSP脚本表达式中的变量或表达式后面不能有分号(;)
2.3、声明 <%! %> 表示在类中定义全局成员,和静态块。
3、JSP注释
JSP注释:<%-- 被注释的内容 --%> 特点:安全,省流量 (不会发送给客户端)
网页注释:<!-- 网页注释 --> 特点:不安全,费流量
4、3指令
5、6动作
6、9内置对象*****
五、jsp的3个指令
JSP指令(directive)是为JSP引擎而设计的,它们并不直接产生任何可见输出,而只是告诉引擎如何处理JSP页面中的其余部分。
在JSP 2.0规范中共定义了三个指令:
page指令
Include指令
taglib指令
语法:
<%@ 指令名称 属性1=“属性值1” 属性2=“属性值2”。。。%>
或者:
<%@ 指令名称 属性1=“属性值1”%>
<%@ 指令名称 属性2=“属性值2”%>
如:<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%@ page language="java" %>
<%@ page import="java.util.*" %>
1、page:
作用:用于定义JSP页面的各种属性
2、include:
静态包含:把其它资源包含到当前页面中。
<%@ include file="/include/header.jsp" %>
动态包含:
<jsp:include page="/include/header.jsp"></jsp:include>
两者的区别:翻译的时间段不同
前者:在翻译时就把两个文件合并
后者:不会合并文件,当代码执行到include时,才包含另一个文件的内容。
原则:能用静的就不用动的。
3、taglib
作用:在JSP页面中导入JSTL标签库。替换jsp中的java代码片段。
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
六、jsp的6个动作
使用标签的形式来表示一段java代码。
如: <jsp:include page="2.jsp"></jsp:include>
<jsp:include > 动态包含
<jsp:forward> 请求转发
<jsp:param> 设置请求参数
<jsp:useBean> 创建一个对象
<jsp:setProperty> 给指定的对象属性赋值
<jsp:getProperty> 取出指定对象的属性值
七、jsp的9个内置对象
指在JSP的<%=%> 和<% %>中可以直接使用的对象
|
对象名
|
类型
|
说明
|
|
request
|
javax.servlet.http.HttpServletRequest
|
|
|
response
|
javax.servlet.http.HttpServletResponse
|
|
|
session
|
javax.servlet.http.HttpSession
|
由session="true"开关
|
|
application
|
javax.servlet.ServletContext
|
|
|
exception
|
java.lang.Throwable
|
由isErrorPage="false"开关
|
|
page
|
java.lang.Object当前对象this
|
当前servlet实例
|
|
config
|
javax.servlet.ServletConfig
|
|
|
out
|
javax.servlet.jsp.JspWriter
|
字符输出流,相当于 printWriter对象
|
|
pageContext
|
javax.servlet.jsp.PageContext
|
pageContext(重要)
1、本身也是一个域对象:它可以操作其它三个域对象(request session application)的数据
2、它可以创建其它的8个隐式对象
在普通类中可以通过PageContext获取其他JSP隐式对象。自定义标签时就使用。
3、提供了的简易方法
pageContext.forward("2.jsp");
pageContext.include("2.jsp");
八、四大域对象:实际开发
PageContext : pageConext 存放的数据在当前页面有效。开发时使用较少。
ServletRequest: request 存放的数据在一次请求(转发)内有效。使用非常多。
HttpSession: session 存放的数据在一次会话中有效。使用的比较多。如:存放用户的登录信息,购物车功能。
ServletContext: application 存放的数据在整个应用范围内都有效。因为范围太大,应尽量少用。
九、EL表达式
1、EL概述和基本语法
EL表达式:expression language 表达式语言
要简化jsp中java代码开发。
它不是一种开发语言,是jsp中获取数据的一种规范
2、EL的具体功能
a、获取数据
${student.name}== ${student['name']} == ${student["name"]}
b、运算
${empty str}
c、隐式对象:11个
|
EL隐式对象引用名称
|
类型
|
JSP内置对象名称
|
说明
|
|
pageContext
|
javax.servlet.jsp.PageContext
|
pageContext
|
一样的
|
|
pageScope
|
java.util.Map<String,Object>
|
没有对应的
|
pageContext范围中存放的数据,页面范围
|
|
requestScope
|
java.util.Map<String,Object>
|
没有对应的
|
请求范围数据
|
|
sessionScope
|
java.util.Map<String,Object>
|
没有对应的
|
会话范围数据
|
|
applicationScope
|
java.util.Map<String,Object>
|
没有对应的
|
应用范围数据
|
|
param
|
java.util.Map<String,String>
|
没有对应的
|
一个请求参数
|
|
paramValues
|
java.util.Map<String,String[]>
|
没有对应的
|
重名请求参数
|
|
header
|
java.util.Map<String,String>
|
没有对应的
|
一个请求消息头
|
|
headerValues
|
java.util.Map<String,String[]>
|
没有对应的
|
重名请求消息头
|
|
initParam
|
java.util.Map<String,String>
|
没有对应的
|
web.xml中全局参数
|
|
cookie
|
java.util.Map<String,Cookie>
|
没有对应的
|
key:cookie对象的name值
|
十、JSTL
1、什么是JSTL
JSTL(JavaServerPages Standard Tag Library)JSP标准标签库
2、JSTL的作用
使用JSTL实现JSP页面中逻辑处理。如判断、循环等。
3、使用JSTL
1)在JSP页面添加taglib指令
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
2)使用JSTL标签
<c;if test=""></c:if>
4、常用标签介绍
核心标签库:
> 通用标签: set、 out、 remove
> 条件标签:if choose
> 迭带标签:foreach、for(类型 变量名:数组或集合)
---------------------------------------------------------------------------------------------------
02_第二阶段Java web ★★ day12 ★ WEB开发笔记
一、JavaWeb开发模式
C/S:客户端 / 服务器 (胖客户端)
B/S:浏览器 / 服务器 (瘦客户端)
JavaBean:
就是一个普通类(实体bean),包含三样标准:一个无参构造、私有属性、公共的getter和setter方法
1、Model1模式
JSP + JavaBean
2、Model2模式
JSP + Servlet + JavaBean
MVC:开发模式
M: Model模型 JavaBean|四种作用域
V:view视图 JSP
C:Controller控制器 Servlet
分层思想:强内聚、弱耦合
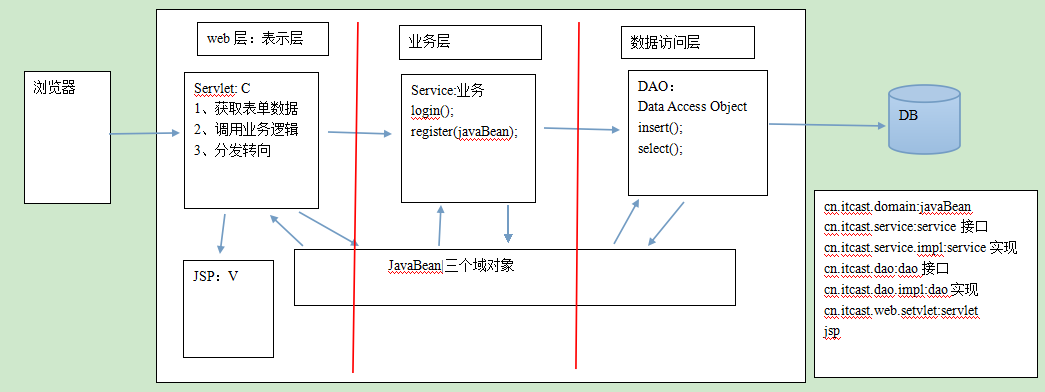
------------------------------------------------------------------------------------------------
02_第二阶段Java web ★★ day13 ★ 1、事务
02_第二阶段Java web ★★ day13 ★ 2、连接池
事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部不成功
Mysql中的事务
a、mysql引擎是支持事务的
b、mysql默认自动提交事务。每条语句都处在单独的事务中。
c、手动控制事务
开启事务:start transaction | begin
提交事务:commit
回滚事务:rollback
(
http://www.cnblogs.com/ymy124/p/3718439.html
1.MyISAM:不支持事务,用于只读程序提高性能
2.InnoDB:支持ACID事务、行级锁、并发
3.Berkeley DB:支持事务
)
JDBC控制事务语句
•Connection.setAutoCommit(false); start transaction
•Connection.rollback(); rollback
•Connection.commit(); commit
事务的特性(面试题)
原子性:指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性:事务必须使数据库从一个一致性状态变换到另外一个一致性状态。转账前和转账后的总金额不变。
隔离性:事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性:指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
事务的隔离级别
赃读:指一个事务读取了另一个事务未提交的数据。
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。一个事务读取到了另一个事务提交后的数据。(update)
虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(insert)
如果读到对方提交的update语句的结果,是不可重复读。如果读到对方insert后的结果,是虚读。
数据库通过设置事务的隔离级别防止以上情况的发生:
* 1、READ UNCOMMITTED: 赃读、不可重复读、虚读都有可能发生。
* 2、READ COMMITTED: 避免赃读。不可重复读、虚读都有可能发生。(oracle默认的)
* 4、REPEATABLE READ:避免赃读、不可重复读。虚读有可能发生。(mysql默认)
* 8、SERIALIZABLE: 避免赃读、不可重复读、虚读。
级别越高,性能越低,数据越安全
mysql中:
查看当前的事务隔离级别:SELECT @@TX_ISOLATION;
更改当前的事务隔离级别:SET TRANSACTION ISOLATION LEVEL 四个级别之一。
设置隔离级别必须在事务之前
JDBC控制事务的隔离级别
设置隔离级别:必须在开启事务之前。
Connection.setTransactionIsolation(int level);
一、数据库连接池
1、连接池原理:(面试)
目的:解决建立数据库连接耗费资源和时间很多的问题,提高性能。
2、编写标准的数据源
自定义数据库连接池要实现javax.sql.DataSource接口,一般都叫数据源。
3、编写数据源时遇到的问题及解决办法
a、装饰设计模式:使用频率很高
目的:改写已存在的类的某个方法或某些方法,装饰设计模式(包装模式)
口诀:
1、编写一个类,实现与被包装类相同的接口。(具备相同的行为)
2、定义一个被包装类类型的变量。
3、定义构造方法,把被包装类的对象注入,给被包装类变量赋值。
4、对于不需要改写的方法,调用原有的方法。
5、对于需要改写的方法,写自己的代码。
public class MyConnection implenents Connection {
}
(
装饰者模式:在不必改变原类文件和使用继承的情况下,动态地扩展一个对象的功能。它是通过创建一个包装对象,也就是装饰来包裹真实的对象。
)
b、默认适配器:装饰设计模式一个变体
1.编写一个类,实现与被包装类相同的接口。(具备相同的行为)
2.定义一个被包装类类型的变量。
3.定义构造方法,把被包装类的对象注入,给被包装类变量赋值。
4.对于不需要改写的方法,调用原有的方法。
public class ConnectionWrapper implements Connection {
}
1.编写一个类,继承包装类适配器。
2.定义一个被包装类类型的变量
3.定义构造方法,把被包装类的对象注入,给被包装类变量赋值
4.对于不需要改写的方法,调用原有的方法
public class MyConnection1 extends ConnectionWrapper {
}
DBCP
DBCP:Apache推出的Database Connection Pool
使用步骤:
> 添加jar包 commons-dbcp-1.4.jar commons-pool-1.5.6.jar
> 添加属性资源文件
> 编写数据源工具类
(
DBCPUtils.class.getClassLoader().getResourceAsStream("dbcpconfig.properties")
这个getResourceAsStream能把资源文件作为输入流输入
InputStream getResourceAsStream(String name)
static {}
静态代码块只在类初始化的时候被执行一次
)
C3P0
使用步骤:
1、添加jar包
2、编写配置文件
c3p0-config.xml,放在classpath中,或classes目录中
3、编写工具类:
5、用JavaWeb服务器管理数据源:Tomcat
开发JavaWeb应用,必须使用一个JavaWeb服务器,JavaWeb服务器都内置数据源。
Tomcat:(DBCP)
数据源只需要配置服务器即可。
配置数据源的步骤:
1、拷贝数据库连接的jar到tomcatlib目录下
2、配置数据源XML文件
a)如果把配置信息写在tomcat下的conf目录的context.xml中,那么所有应用都能使用此数据源。
b)如果是在当前应用的META-INF中创建context.xml, 编写数据源,那么只有当前应用可以使用。
3、使用连接池
JNDI:java nameing directory interface
JNDI容器就是一个Map
|
key(String)
|
value(Object)
|
|
path+name
|
对象
|
|
path+"jdbc/day16"
|
DataSource对象
|
二、自定义JDBC框架(练技术)
1、数据库元信息的获取(很简单、很无聊、很重要)
a、元信息:(Meta Data)指数据库或表等的定义信息。
2、自定义JDBC框架
反射;策略设计模式;
----------------------------------------------------------------------------------------------------------
02_第二阶段Java web ★★ day14 ★ DBUTils笔记
一、DBUtils介绍 apache
DBUtils是java编程中的数据库操作实用工具,小巧简单实用。
DBUtils封装了对JDBC的操作,简化了JDBC操作。可以少写代码。
1.对于数据表的读操作,他可以把结果转换成List,Array,Set等java集合,便于程序员操作;
2.对于数据表的写操作,也变得很简单(只需写sql语句)
3.可以使用数据源,使用JNDI,数据库连接池等技术来优化性能--重用已经构建好的数据库连接对象
二、DBUtils的三个核心对象
> QueryRunner类
> ResultSetHandler接口
> DBUtils类
QueryRunner类
QueryRunner中提供对sql语句操作的API.
它主要有三个方法
query() 用于执行select
update() 用于执行insert update delete
batch() 批处理
ResultSetHandler接口
用于定义select操作后,怎样封装结果集.
DbUtils类
它就是一个工具类,定义了关闭资源与事务处理的方法
三、Dbutils快速入门
> 导入jar包
> 创建QueryRunner对象
> 使用query方法执行select语句
> 使用ResultSetHandler封装结果集
> 使用DbUtils类释放资源
四、QueryRunner对象
1.1 构造函数:
> new QueryRunner(); 它的事务可以手动控制。
也就是说此对象调用的方法(如:query、update、batrch)参数中要有Connection对象。
> new QueryRunner(DataSource ds); 它的事务是自动控制的。一个sql一个事务。
此对象调用的方法(如:query、update、batrch)参数中无需Connection对象。
1.2 方法
<T> T query(String sql, ResultSetHandler<T> rsh, Object... params)
等
五、ResultSetHandler接口
ResultSetHandler下的所有结果处理器
//ArrayHandler:适合取1条记录。把该条记录的每列值封装到一个数组中Object[]
//ArrayListHandler:适合取多条记录。把每条记录的每列值封装到一个数组中Object[],把数组封装到一个List中
//ColumnListHandler:取某一列的数据。封装到List中。
//KeyedHandler:取多条记录,每一条记录封装到一个Map中,再把这个Map封装到另外一个Map中,key为指定的字段值。
//MapHandler:适合取1条记录。把当前记录的列名和列值放到一个Map中
//MapListHandler:适合取多条记录。把每条记录封装到一个Map中,再把Map封装到List中
//ScalarHandler:适合取单行单列数据
BeanHandler
BeanListHandler
六、DBUtils控制事务的开发
(一个业务的执行过程中应该使用同一个connection )
七、ThreadLocal
模拟ThreadLocal的设计,让大家明白他的作用。
public class ThreadLocal{
private Map<Runnable,Object> container = new HashMap<Runnable,Object>();
public void set(Object value){
container.put(Thread.currentThread(),value);//用当前线程作为key
}
public Object get(){
return container.get(Thread.currentThread());
}
public void remove(){
container.remove(Thread.currentThread());
}
}
八、完成案例
-------------------------------------------------------------------------------------------------------
02_第二阶段Java web ★★ day15 ★ 分页与案例
什么是分页及其作用
分页就是将数据以多页展示出来,使用分页的目的是为了提高用户的感受
物理分页
l只从数据库中查询出要显示的数据
l优点:不占用很多内存
l缺点:速度比较低,每一次都要从数据库中获取
逻辑分页
l从数据库中将所有记录查找到,存储到内存中,需要什么数据
l直接从内存中获取.
l优点:速度比较快
l缺点:占用比较多的内存,如果数据比较多,可以出现内在溢出。
l 数据实时更新需要单独处理.
利用mysql的limit,进行物理分页。
select * from 表名 limit m,n;
m是从0开始,代表是第几条记录
n代表显示多少条记录
例如
•select * from person limit 4,10;
从第五条记录开始,显示10条.
分页实现原理分析
l1.知道一共有多少条记录
•select count(*) from 表;
2.知道每一页显示多少条记录
•人为定义的.
3.一共有多少页
l 1.总页数=总条数%每页条数==0?总条数/每页条数:总条数/每页条数+1
l 2.总页数=Math.ceil(总条数*1.0/每页条数);
4.当前页码
l 默认值为1,代表第一页.
l 当点击上一页,下一页,就是对页码进行+1 -1操作.
5.需要当前页的数据
l 例如:每页显示五条,要查询第三页数据
l select * from 表 limit(3-1)*5,5;
用(当前页码-1)*每页条数,就求出了开始的记录位置,在向下查找每页数个 记录。就得到了这页的数据.
String sql = "select * from book limit 0,3";
int currentPage = 3; 当前页
int pageSize = 3; 每页显示和条数
int count = select count(*) from book; 总记录数
int totalPage = Math.ceil(count*1.0/pageSize); 共页数
count%pageSize==0?count/pageSize:count/pageSize+1;
SELECT * FROM book LIMIT (currentPage-1)*pageSize,pageSize;-- 第一个参数:从哪条开始查 第二个参数:查几条
---------------------------------------------------------------------------------
02_第二阶段Java web ★★ day16 ★ ajax
(
http://www.w3school.com.cn/xhtml/xhtml_intro.asp
- XHTML 指可扩展超文本标签语言(EXtensible HyperText Markup Language)。
- XHTML 的目标是取代 HTML。
- XHTML 与 HTML 4.01 几乎是相同的。
- XHTML 是更严格更纯净的 HTML 版本。
- XHTML 是作为一种 XML 应用被重新定义的 HTML。
- XHTML 是一个 W3C 标准。
XHTML与HTML最主要的不同
- XHTML 元素必须被正确地嵌套。
- XHTML 元素必须被关闭。
- 标签名必须用小写字母。
- XHTML 文档必须拥有根元素。
其他语法规则
- 属性名称必须小写
- 属性值必须加引号
- 属性不能简写
- 用 Id 属性代替 name 属性
- XHTML DTD 定义了强制使用的 HTML 元素
DOM (文档对象模型(Document Object Model))
是W3C组织推荐的处理可扩展标志语言的标准编程接口。在网页上,组织页面(或文档)的对象被组织在一个树形结构中,用来表示文档中对象的标准模型就称为DOM。
XSLT 是一种用于将 XML 文档转换为 XHTML 文档或其他 XML 文档的语言。
XPath 是一种用于在 XML 文档中进行导航的语言。
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
DHTML是Dynamic HTML的简称,就是动态的html(标准通用标记语言下的一个应用),是相对传统的静态的html而言的一种制作网页的概念。
)
