
《编程之法》
第一章 字符串
1.1 字符串的旋转
问题:"abcdef" -> "defabc"
三步反转法:先将字符串给为两个部分,各自反转,最后整体反转。
O(N) O(1)
1.2 字符串的包含
问题:快速判断短字符串b中的所有字符是否都在长字符串a中
"ABCD" "BAD" true
位运算法:将长字符串a的字符都放入散列表里,位运算实质是用一个整数代替了散列表
1.3 字符串的全排列
一、递归 二、字典序排列(部分旋转,很巧妙)
1.4 字符串转换成整数
问题:输入字符串"123" 输出整数123
从左至右扫描字符串中的每个字符,把之前扫描得到的数字乘以10,再加上当前字符表示的数字
需要注意细节:判断是否为空,判断是否溢出
判断溢出:一、转换后使用long long类型 二 比较n和MAX_INT/10的大小(注意当n==MAX_INT/10时,最后的数字跟MAX_INT%10的大小)
1.5 回文判断
问题:判断字符串是否是回文串
解法一、两头往中间扫 解法二、从中间往两头扫
链表回文:使用快慢指针法。先定位到链表中间位置,将链表后半段逆置,两个指针同时从链表头部和中间开始逐一向后比较。
栈回文:字符串全部入栈,出栈得到逆置串,逐一比较。
1.6 最长回文子串
问题:求最长回文子串的长度
解法一、中心扩展法
解法二、Manacher算法(插入#解决奇偶问题;在每个位置上同时向左和向右扩展时不重复计算,加速扩展)
参考:https://segmentfault.com/a/1190000003914228
时间复杂度 O(n)
Manacher存储每个节点的对称长度,去除每次对比的冗余。
第二章 数组
2.1 寻找最小的K个数
问题:有n个整数,找出其中最小的K个数
解法一、全部排序(快排) O(nlogn)
解法二、部分排序 O(NK)
解法三、用堆代替数组 O(nlogk)
解法四、线性选择算法
类似快排,但是只划分出需要的k个数,不排序到底
平均O(n)
三元组的数量
给出一个数列 a1, a2, a3, ..., an 和m个查询. 对于每一个查询(i, j, k)找出从ai到aj的升序排列数列中的第k个数.
参考: https://jecvay.com/2014/08/poj2104-bucket-segmentation.html
朴素的方法就是对区间进行排序, 然后找出第k个
2.2 寻找和为定值的两个数
问题:输入一个数组和一个数字,在数组中查找两个数,使得它们的和正好是输入的那个数字。
example: 例如输入数组1、2、4、7、11、15和数字15。由于4+11=15,因此输出4和11。
解法一:散列映射(空间换时间)
根据散列查找另一个数是否也在数组中
时间O(n) 空间O(n)
解法二:排列夹逼
若无需,先排成有序。
再二分查找,对于n个数,需要时间 O(nlogn) ,空间O(1)
数组有序情况下,两个指针分别从头尾向中间扫描,时间O(n),空间O(1)
加上排序,时间O(nlogn),空间O(1)
2.3 寻找和为定值的多个数
问题:输入两个整数n和sum,要求从数列1,2,3,...,n中随意取出几个数,使得它们的和等于sum,请将其中所以可能的组合列出来。
解法一:n问题转换为n-1问题
转换成取第n个和不取第n个数的区别,从后向前递归,sum不断变小,n也变小。
当sum==n则该情况符合条件,当n<=0 || sum<=0 则跳出
每次递归两种情况,取和不取第n个数
典型的01背包问题
解法二:回溯剪枝
在线参考:https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/02.03.md
这个问题属于子集和问题(也是背包问题)。本程序采用回溯法+剪枝,其中X数组是解向量,t=∑(1,..,k-1)Wi*Xi, r=∑(k,..,n)Wi,且
- 若t+Wk+W(k+1)<=M,则Xk=true,递归左儿子(X1,X2,..,X(k-1),1);否则剪枝;
- 若t+r-Wk>=M && t+W(k+1)<=M,则置Xk=0,递归右儿子(X1,X2,..,X(k-1),0);否则剪枝;
本题中W数组就是(1,2,..,n),所以直接用k代替WK值。
意思是,从最少的开始加
如果这个加上这个数还不满足,即<=M,这加上这个数向后递归,因为加上这个数有成立存在。
如果少了这个数,前面的选择t加上后面的所有数r>=M,并且前面的选择t加上当前数<=M,则说明可以不要这个数有成立存在的。
问题扩展:01背包问题
有N件物品和一个容量为V的背包。放入第i件物品耗费的费用是Ci,得到的价值是Wi。求解将哪些物品装入背包可使价值总和最大。
物体转换为:如果放第i件物品,如果不放第i件物品
伪代码如下:
F[0,0...V] ← 0
for i ← 1 to N
for v ← Ci to V
F[i, v] ← max{F[i-1, v], F[i-1, v-Ci] + Wi }
这段代码的时间和空间复杂度均为 O(VN),其中时间复杂度应该已经不能再优化了,但空间复杂度却可以优化到O(V)
背包问题解释参考:http://blog.csdn.net/mu399/article/details/7722810
更多优化参考:背包问题九讲 http://love-oriented.com/pack/
优化空间复杂度,就是只存储i-1的结果,
2.4 最大连续子数组和
问题:给定一个整数数组,数组里可能有正数、负数和零。数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和。 求所有子数组的和的最大值。
解法一:蛮力枚举
三个for循环三层遍历,求出数组中每一个子数组的和
时间复杂度 O(n^3)
解法二:动态规划
令currSum为当前最大子数组的和,maxSum为最后要返回的最大子数组的和,我们往后扫描。current(j) = max{0, currSum[j-1]}+a[j] ,当currSum > maxSum,则更新maxSum = currSum 。
时间复杂度 O(n)
长度最短的连续子序列
http://blog.csdn.net/jaster_wisdom/article/details/52153685
两个指针,一前一后,一大于等于sum,后面的指针就前移,直到刚好大于等于sum,记录,前面的指针再前移。
最大子矩阵和
转化为最大子序列求解的思路是:固定第i列到第j列的范围,寻找在这个范围内的最大子矩阵,这个寻找过程,把每行第i列上的元素到第j列的元素分别求和,就转变为了一维的情况。由于有C(n,2)种列的组合,而求一维的子序列需要n的时间,所以,总体上时间复杂度为O(n^3)。
http://www.cnblogs.com/pangxiaodong/archive/2011/09/02/2163445.html
2.5 跳台阶问题
问题:一个台阶总共有n 级,如果一次可以跳1 级,也可以跳2 级,求总共有多少总跳法。
解法一:递归
/ 1 n = 1
f(n)= 2 n = 2
\ f(n-1) + f(n-2) n > 2
就是我们平常所熟知的Fibonacci数列问题
解法二:递推
解法一用的递归的方法有许多重复计算的工作,我们可以从后往前推,一步步利用之前计算的结果递推。
初始化时,dp[0]=dp[1]=1,然后递推计算即可:dp[n] = dp[n-1] + dp[n-2]。
2.6 奇偶数排序
问题:输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。要求时间复杂度为O(n)。
使用快速排序的思想
解法一:一头一尾指针往中间扫描
一头一尾两个指针往中间扫描,如果头指针遇到的数比主元大且尾指针遇到的数比主元小,则交换头尾指针所分别指向的数字;
解法二:一前一后两个指针往后扫描
一前一后两个指针同时从左往右扫,如果前指针遇到的数比主元小,则后指针右移一位,然后交换各自所指向的数字。
2.7 荷兰国旗
问题:现有n个红白蓝三种不同颜色的小球,乱序排列在一起,请通过两两交换任意两个球,使得从左至右,依次是一些红球、一些白球、一些蓝球。
使用快速排序的思想
需要用到三个指针:一个前指针begin,一个中指针current,一个后指针end,current指针遍历整个数组序列,当
- current指针所指元素为0时,与begin指针所指的元素交换,而后current++,begin++ ;
- current指针所指元素为1时,不做任何交换(即球不动),而后current++ ;
- current指针所指元素为2时,与end指针所指的元素交换,而后,current指针不动,end-- 。
2.8 矩阵相乘
问题:请编程实现矩阵乘法,并考虑当矩阵规模较大时的优化方法。
解法一:暴力解法
其复杂度为O(n^3)
解法二:Strassen算法
德国数学家施特拉森了一系列工作使得最终的时间复杂度降低到了O(n^2.80)。
参考 矩阵乘法的Strassen算法详解:http://www.mamicode.com/info-detail-673908.html
2.9 完美洗牌算法
解法一:蛮力变换
1.1、步步前移
时间复杂度 O(N^2)
1.2、中间交换
时间复杂度依然为 O(N^2)
解法二:完美洗牌算法
直接使用 位置置换算法 ,需要另外一个数组 (时间复杂度O(N),空间复杂度O(1))
走环算法:
(太复杂了!!!暂时不看了???)
第3章 树
两种被广泛使用的数 ------ 红黑树和B树。
有了红黑树,还需要B树的原因
数据量很大时,内存放不下,为了减少磁盘读写的开销,想办法降低树的高度,有多个孩子的B树应运而生。
上面几层被反复查询的可以存在内存中,大部分下层数据存在磁盘上。
3.1 统计出现次数最多的数据
题目:有千万或上亿的数据,且数据有重复,要求统计其中出现次数最多的前n个数据。
解法一:用hash_map进行频率统计
用hash_map统计每个数据出现的次数,然后利用堆取出前n个出现次数最多的数据。
(
参考 分而治之:hash映射 + hash_map统计 + 排序:
http://taop.marchtea.com/09.03.html
- Hash取模是一种等价映射,不会存在同一个元素分散到不同小文件中去的情况,即这里采用的是%1000算法,那么同一个IP在hash后,只可能落在同一个文件中,不可能被分散的。
)
解法二:用红黑树进行频率统计
用红黑树进行频率统计,再用堆取出前n个出现次数最多的数据。
红黑树 本质上是一颗 二叉查找树
二叉查找树 也称 有序二叉树 已排序二叉树
二叉查找树 平均时间复杂度 O(log n) 最坏情况下 时间复杂度O(n)
性质
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
红黑树原理证明参考:
http://www.cnblogs.com/skywang12345/p/3245399.html
一棵含有n个节点的红黑树的高度至多为2log(n+1),它的包含的内节点个数至少为 2^(h/2)-1个。
证明:
"一棵含有n个节点的红黑树的高度至多为2log(n+1)" 的逆否命题是 "高度为h的红黑树,它的包含的内节点个数至少为 2h/2-1个"。
黑色节点的个数称为该节点的黑高度(x's black height),记为bh(x),由 性质5 得,bh(x)的值是唯一的。
由 性质4 ,得 bh(x) >= h/2 ,只需要证明"高度为h的红黑树,它的包含的内节点个数至少为 2^bh(x)-1个"。
数学归纳法
(01) 当树的高度h=0
(02) 当h>0,且树的高度为 h-1 时
当树的高度为 h 时 x的左右子树,即高度为 h-1 的节点,它包含的节点至少为2^( bh(x)-1)-1 个
节点x所包含的节点至少为 ( 2^(bh(x)-1)-1 ) + ( 2^( bh(x)-1)-1 ) + 1 = 2^(bh(x))-1。即节点x所包含的节点至少为 2^(bh(x))-1。
红黑树能保证在最坏情况下,基本的动态几何操作的时间均为O(logn)
剑指XX游戏(六) - 轻松搞定面试中的红黑树问题
http://blog.csdn.net/silangquan/article/details/18655795
红黑树多用在内部排序,即全放在内存中的。B树多用在内存里放不下,大部分数据存储在外存上时。
红黑树 如果数据基本上是静态的,那么让他们待在他们能够插入,并且不影响平衡的地方会具有更好的性能
数据完全是静态的,做一个哈希表,性能可能会更好一些。
红黑树是有序的,Hash是无序的。
3.2 上亿行数据的快速查询
题目:硬盘上有一个文本,里面是一行一行的人名,请从中找出叫“July”的人。
比较好的方法是建立数据库索引,常见的索引有散列索引和B树索引。
散列索引 无序,不方便查找前后的值。
主流数据库一般采用 B树索引、B+树索引。
为了降低树的高度,采用多叉树结构,产生了B树。
B+树在B树的基础上做了改造,每个叶子节点还存储了指向相邻节点的指针。加快检索多个相邻叶节点的效率。
磁盘读写原理
磁盘上的数据用一个三维地址唯一标识:柱面号、盘面号、块号。
磁盘访问某一数据的时间由三个部分组成:
寻道时间、延迟时间、传输时间
参考 编程之法 电子书:
https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/03.02.md
B树
B 树又叫平衡多路查找树
一颗m阶的B树特性如下:
(1)树中每个节点最多含有m个孩子(m ≥ 2);
(2)除根结点和叶节点外,其他每个节点至少有ceil(m/2)个孩子;
(3)根节点至少有两个孩子(除非B树只有一个节点-根节点);
(4)所有叶节点出现在同一层,叶节点不包含任何关键字信息(每一个NULL指针即当做叶子结点);
(5)每个非终端节点含有n个关键字,即(n,P0,K1,P1,K2,P2,...,Kn,Pn)。其中Ki(i = 1,2,...,n)为关键字,且关键字按顺序升序排列Ki-1且指针Pi-1指向子树中的所有节点的关键字均小于Ki且都大于Ki-1,关键字的个数n必须满足ceil(m/2)-1≤n≤m-1。比如,有j个孩子的非叶节点恰好有j-1个关键字。
对于一棵含有N个关键字,m阶的B树来说(据B树的定义可知:m满足:ceil(m/2)<=m<=m,m阶即代表树中任一结点最多含有m个孩子,如5阶代表每个结点最多5个孩子,或俗称5叉树),且从1开始计数的话,其高度h为:

B+树
一棵m阶的B+树和m阶的B树的异同点在于:
- 有n棵子树的结点中含有n个关键字; (有些资料上说与B 树n棵子树有n-1个关键字 保持一致,无关紧要,只是实现不同)
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
B+树的磁盘读写代价更低
B+树的查询效率更稳定,支持基于范围的查询
B*树
在B+树的基础上(所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针),B*树中非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。
总结如下:
- B树:有序数组+平衡多叉树;
- B+树:有序数组链表+平衡多叉树;
- B*树:一棵丰满的B+树。
顺便说一句,无论是B树,还是B+树、b树,由于根或者树的上面几层被反复查询,所以这几块可以存在内存中,换言之,B树、B+树、B树的根结点和部分顶层数据在内存中,大部分下层数据在磁盘上。
3.3 最近公共祖先问题
题目:求二叉树的任意两个节点的最近公共祖先。
最近公共祖先简称LCA(Lowest Common Ancestor)
解法一:暴力对待
1.1、是二叉查找树
从树根开始:
- 如果当前结点t 大于结点u、v,说明u、v都在t 的左侧,所以它们的共同祖先必定在t 的左子树中,故从t 的左子树中继续查找;
- 如果当前结点t 小于结点u、v,说明u、v都在t 的右侧,所以它们的共同祖先必定在t 的右子树中,故从t 的右子树中继续查找;
- 如果当前结点t 满足 u <t < v,说明u和v分居在t 的两侧,故当前结点t 即为最近公共祖先;
- 而如果u是v的祖先,那么返回u的父结点,同理,如果v是u的祖先,那么返回v的父结点。
1.2、不是二叉查找树
有父节点指针时,可以转换为寻找两个单项链表的第一个公共节点。
没有父指针时,可以从根节点到v和u节点递归查找。
一个很大的弊端就是:如需N 次查询,则总体复杂度会扩大N 倍,故这种暴力解法仅适合一次查询,不适合多次查询。
总体来说,由于可以把LCA问题看成是询问式的,即给出一系列询问,程序对每一个询问尽快做出反应。故处理这类问题一般有两种解决方法:
- 一种是在线算法,相当于循序渐进处理;
- 另外一种则是离线算法,如Tarjan算法,相当于一次性批量处理,一开始就知道了全部查询,只待询问。
解法二:Tarjan算法
(太复杂了!!!暂时不看了???)
解法三:转换为RMQ问题
(太复杂了!!!暂时不看了???)
第4章 查找
4.1 有序数组的查找
给定一个排好序的数组,查找某个数是否在这个数组中,请编程实现。
解法:二分法
注意:一点是判断循环体是否终止的语句的编写,另一点是边界值left、right和区间值这三个地方要保持一致。
4.2 行列递增矩阵的查找
行和列都是递增的矩阵(杨氏矩阵),查找是否含有某个整数。
解法一:分治法
若要找的数介于对角线上相邻的两个数,则可以排除掉左上和右下,在左下和右上的两个相邻小郡主内继续递归查找。
解法二:定位法
从右上角向左下角走,比目标数大向左走,比目标数小向下走。
时间复杂度 O(m+n)
拓展:矩阵里的中位数
http://zhiqiang.org/blog/science/computer-science/median-algorithm-of-ordered-matrix.html
4.3 出现次数超过一半的数
题目:数组中有一个数字出现的次数超过了数组长度的一半,找出这个数字。
解法一:排序
先排序(可用快排),后找 n/2 处的数
O(nlogn)
解法二:散列表
散列表统计次数
时间 O(n) 空间 O(n)
解法三:每次删除两个不同的数
剩下的数就是要找的
时间 O(n) 空间 O(1)
解法四:记录两个值
https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/04.03.md
candidate nTimes
4.4 字符串的查找
题目:查找模式串P在文本串S中的位置
解法一:蛮力匹配
解法二:KMP算法
next数组匹配
计算方法:
- 计算最长前缀和后缀 最大长度表
- 递推
- 递推优化:next[j] = next[k]
时间复杂度;O(m+n)
还有更快的算法:BM算法 和 Sunday 算法
//TODO: 参考代码\解释
第5章 动态规划
在图算法中:
广度优先搜索 寻找最短路径 采取队列的方法
最小生成树 最小代价连接所有点 贪心,其中的Prim是贪心+加权队列
Dijkstra 寻找单源最短路径 贪心法+非负加权队列
Floyd 寻找多结点对之间的最短路径 动态规划
5.1 最大连续乘积子数组
解法一:蛮力轮询
两个for循环
时间复杂度:O(n^2)
解法二:动态规划
在数组中找到一个子数组maxend,使它的乘积最大,同时再找到乘积最小的子数组minend
状态转移方程:
maxend = max(max(maxend * a[i], minend * a[i]), a[i]);
minend = min(min(maxend * a[i], minend * a[i]), a[i]);
动态规划:
动态规划一般用来求解最优化问题,其适用条件是要求待求解的最优化问题具备两个因素:最优子结构和子问题重叠。通过求解一个个最优子问题,将解存入一张表中,当后续子问题的求解需要用到之前子问题的解时直接查表,每次查表的代价为常数时间。
示例:
求A到B的最短路径
思路:枚举所有的路径
求二维矩阵m×n,使得路径经过的元素和最小的路径,每次只能向右或向下走。
思路:深度优先方程求解:path[i][j]=min(path[i][j-1], path[i-1, j])+matrix[i][j]
参考:http://blog.csdn.net/yang20141109/article/details/51541332
空间复杂度可以优化到O(m)
全排列 和 排列组合公式:
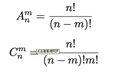
求解过程关键:
- 状态的定义
- 方案的枚举(仅枚举必要的)
- 最优子问题(一个状态的最优值取决于达到这个状态的全部子状态最优值) 和无后效性保证(状态之间的最优值不互相影响)
- 子问题有重叠
- 编写状态转移方程(当前节点的值完全由其前驱结点确定)
与贪心法的区别:
贪心法是特殊的动态规划(子问题不重叠),贪心法是“最优子结构且局部最优”,动态规划是“最优独立重叠子结构且全局最优”
举一反三:
给定一个长度为N的整数数组,只允许用乘法,不能用除法,计算任意(N-1)个数的组合中乘积最大的一组,并写出算法的时间复杂度
参考:
http://blog.csdn.net/hishentan/article/details/37094529
只需要从头至尾和从尾至投扫描数组两次得到数组s[]和t[],进而得到p[i]=s[i-1]xt[i+1],时间复杂度O(N)
5.2 字符串编辑距离
(
参考:[经典面试题]字符串编辑距离
http://blog.csdn.net/sunnyyoona/article/details/43853383
(1)一步操作之后,再将A[2…lenA] 和 B[1…lenB]变成相同的字符串。
(2)一步操作之后,再将A[1…lenA] 和 B[2…lenB]变成相同的字符串。
(3)一步操作之后,再将A[2…lenA] 和 B[2…lenB]变成相同的字符串。
)
状态转移方程:
dp[i][j] =min {
dp[i-1][j] + 1 , S[i]不在T[0…j]中
dp[i-1][j-1] + 1/0 , S[i]在T[j]
dp[i][j-1] + 1 , S[i]在T[0…j-1]中
}
//dp[i,j]表示表示源串S[0…i] 和目标串T[0…j] 的最短编辑距离
dp[i, j] = min { dp[i - 1, j] + 1, dp[i, j - 1] + 1, dp[i - 1, j - 1] + (s[i] == t[j] ? 0 : 1) }
//分别表示:删除1个,添加1个,替换1个(相同就不用替换)。
5.3 格子取数问题
https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/05.03.md
状态转移方程:
if(i!=j)
DP[6,2,3] = Max(DP[5,1,2] ,DP[5,1,3],DP[5,2,2],DP[5,2,3]) + 6,2和6,3格子中对应的数值
else
DP[6,2,2] = Max(DP[5,1,1],DP[5,1,2],DP[5,2,2]) + 6,2格子中对应的数值
(为什么i==j时少了DP[5,2,1] //TODO)
5.4 交替字符串
咱们可以考虑下用动态规划的方法,令dp[i][j]代表s3[0...i+j-1]是否由s1[0...i-1]和s2[0...j-1]的字符组成
- 如果s1当前字符(即s1[i-1])等于s3当前字符(即s3[i+j-1]),而且dp[i-1][j]为真,那么可以取s1当前字符而忽略s2的情况,dp[i][j]返回真;
- 如果s2当前字符等于s3当前字符,并且dp[i][j-1]为真,那么可以取s2而忽略s1的情况,dp[i][j]返回真,其它情况,dp[i][j]返回假
(不是特别理解//TODO)
第6章 海量数据处理
6.1 基础知识:STL容器
STL容器分为:
序列式容器:vector、list、deque、stack、queue、heap等
关联式容器:每个元素都有键值对
C++标准之前,旧标准规定标准的关联式容器分为set(集合)和map(映射)。
红黑树 (有自动排序)
- set/map (map同时拥有键和值,set的键就是值)
- multiset/multimap (允许重复键值)
hashtable (无序)
- hash_map/hash_set (map同时拥有键和值,set的键就是值)
- hash_multiset/hash_multimap (允许重复键值)
6.2 散列分治
题目:寻找访问百度次数最多的IP(TOP IP)
(1)分而治之/散列映射 把大文件的数据映射到若干个小文件中,如hash(IP)%1000
(2)hash_map统计 对每个小文件中的IP进行频率统计,如hash_map(ip, value)
(3)堆/快速排序 排序每个小文件中频率最高的IP
题目:统计100万条查询记录中最热门的10个查询串(寻找热门查询)
占用内存 3000000 x 255 = 765M,可以放进内存,放弃分而治之。
(1)hash_map统计
(2)堆排序、Trie树都可以。时间复杂度:O(n)+O(n'logk)
题目:1G大小文件,每行一个单词,长度不超过16字节,内存大小限制1MB,寻找出现频率最高的100个词
(1)分而治之/散列映射 把大文件的数据映射到若干个小文件中,5000个小文件,每个大小不超过1M
(2)hash_map统计 对每个小文件中的IP进行频率统计,hash_map/trie树都可以。
(3)堆/快速排序 取出每个文件中次数最多的100个词,存入文件,得到5000个文件,归并排序。
题目:海量数据分布在100台电脑,统计出现次数最多的Top 10
解法一:同一个元素只在某一台电脑上
(1)堆排序 求出Top 10最小用最大堆,求最大用最小堆。
(2)组合归并 每台电脑的Top 10组合起来,共1000个数据,求出Top 10
解法二:同一元素可能出现在不同电脑
两种方法:1 重新散列取模,使同一元素只出现在单独的一台电脑 2 蛮力求解,统计每台电脑所有元素的出现个数,相加
题目:10个文件,每个文件大小1GB,每行都是一个查询串query,按频度将query排序。(查询串的重新排列)
解法一:
(1)散列映射 读取10个文件,散列到另外10个文件
(2)hash_map统计
(3)堆排序、快速排序、归并排序 得到10个排序好的文件,再次归并排序(内外排序结合)
解法二:query总量有限,重复次数多,可一次性放入内存。可采用Trie树、hash_map等直接统计,最后排序
解法三:与解法一类似,只是散列后,采用分布式架构来处理(如:MapReduce),最后合并。
题目:a和b两个文件,各存放50亿个URL,每个URL占64字节,内存限制4G,找出a和b文件共同的URL(寻找共同的URL )
(1)分而治之/散列映射
(2)hash_set统计 把一个文件的URL存到hash_set中,遍历另一个小文件中的URL,是否在hash_set里面
举一反三
问题:100万个数中寻找最大的100个数
选取前100个元素排序,利用插入排序的思想遍历所有元素
问题:文件中10亿行单词,统计10个出现次数最多的词
解法一:无法一次性读入内存,采用散列取模的方法。
解法二:用Trie树统计次数,最后排序,如:堆排序。
问题:在海量数据中寻找出现次数最多的数
先散列后取模,映射成小文件,统计。
问题:海量数据中统计出现次数最多的前n个数据
内存能存下,考虑hash_map、搜索二叉树、红黑树等进行统计,最后通过堆排序取出n个次数最多的数据。
问题:1000万个字符串的去重
Trie树比较合适,hash_map也行。
(
问题分类一
次数统计/数值排序问题:
(1)散列成小文件 (可一次性放入内存则不需要)
(2)hash_map (对于单词等可采用Trie树等)
(3)堆/快排 (合并的数据仍然较大时,最后使用外部归并排序)
数值比较问题:
(1)是否有重复,存入hash_set
(2)求前N个数,利用插入排序的思想在外部直接进行排序
问题分类二
同一元素同机器问题:
如上单机处理或者采用分布式架构来处理
同一元素不同机器问题:
重新散列或者暴力求解
)
6.3 多层划分
多层划分本质上是分治的思想,元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后在一个可接受的范围内进行查找。
问题:在2.5亿个整数中寻找不重复的数
类似鸽巢原理,整数个数为2^32,将这2^32个数划分为2^8个区域,然后将数据分到不同的区域,最后不同的区域用位图统计即可。
问题:找出5亿个int型数的中位数
首先将5亿个int型数划分为2^16个区域,然后读取落到各个区域的数,从统计结果可以判断中位数落到哪个区域,并且知道该区域第几个大数刚好是中位数。第二次扫描这个区域的数就可以了。
6.4 MapReduce
MapReduce是一种计算模型,将大批量的工作或者数据分解执行(Map),再将结果合并成最终结果(Reduce)。
MapReduce的原理就是一个归并排序,适用于数据量大而数据种类少以至于可以放入内存的场景。
软件实现是指定一个Map函数,把键值对映射成新的键值对,形成一系列中间结果构成的键值对,然后传给Reduce函数,把具有相同中间形式的键值对合并在一起。
问题:一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到个数中的中数?
方案1:先大体估计一下这些数的范围,比如这里假设这些数都是32位无符号整数(共有2^32个)。我们把0到2^32-1的整数划分为N个范围段,每个段包含2^32/N个整数。比如,第一个段位0到(2^32/N) -1,第二段为2^32/N到(2^32*2/N)-1,…,第N个段为2^32(N-1)/N到2^32-1。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于N^2/2,而在第k-1个机器上的累加数小于N^2/2,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第N^2/2
-x 位。然后我们对第k个机器的数排序,并找出第个数,即为所求的中位数。复杂度是的O(N^2)。
方案2:先对每台机器上的数进行排序。排好序后,我们采用归并排序的思想,将这N个机器上的数归并起来得到最终的排序。找到第N^2/2个便是所求。复杂度是O(N^2lgN^2)的。
6.5 外排序
外排序就是在内存外面的排序。
外排序通常采用的是一种“排序-归并”的策略。在排序阶段,先读入能放在内存中的数据,将其排序后输出到一个临时文件,依次进行,将待排序数据组织为多个有序的临时文件,而后在归并阶段将这些临时文件组合为一个大的有序文件,即为排序结果。
问题实例:给10^7个数据的磁盘文件排序
给定一个文件,里面最多含有n个不重复的正整数,且每个数都小于等于n(n=10^7),请输出一个按小到大升序排列的包含所有输入整数的列表。最多大约1MB的内存空间可用,但磁盘空间足够。要求运行时间5分钟内,10秒为最佳结果。
解法一:位图方案
位图方案要求:
1 输入数据限制在相对较小的范围内
2 数据没有重复
3 其中的每条记录都是单一的整数,没有任何其他与之关联的数据。
上述的位图方案共需要扫描输入数据两次,第一次处理1~5 000 000的数据,大约需要5 000 000/8=625 000字节,即0.625MB,排序后输出。第二次处理5 000 001~10 000 000的数据,也需要0.625MB
现在只有1MB空间,严格来说还是不行。
解法二:多路归并
把大文件分为若干大小的几块,每块进行分别排序,最后完成整个过程的排序。
解法总结:
位图 O(n) 0.625MB
多路归并 O(nlogn) 1MB
多路归并的绝大部分时间浪费在读写磁盘的步骤上。
6.6 位图
位图就是用一个位(bit)来标记某个元素对应的值,键就是该元素。
位图可进行快速查找、判重、删除。
p + (i/8) | (0x01 << (i%8))
这里默认为大端,元素4,存放在第5位。
little-endian就是低字节排放在内存的低地址端,高位字节排放在内存的高地址端。
big-endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
(
X86 ARM 等是小端
KEIL 网络字节序 JAVA默认 是大端
小端 小->大
e684 6c4e
大端前32位应该这样读:e6 84 6c4e
小端前32位应该这样读:4e 6c 84 e6
)
6.7 布隆过滤器
布隆过滤器是一种空间效率很高的随机数据结构,可以看成对位图的扩展。
其结构是一个长度为n的位数组,初始化全为0。当一个元素被加入集合时,通过k个散列函数将这个元素映射成一个位数组中的k个点,并将这k个点全部置为1。
它有一定的误判率。
布隆过滤器可以用来实现数据字典,进行数据的判重或者集合求交集。
6.8 Trie树
Trie树 字典树 单词查找树或键树
常用于统计和排序大量字符串等场景中
核心思想是以空间换时间,利用字符串的公共前缀来降低查询时间的开销。
三个基本性质:
- 根结点不包含字符,除根结点外每个结点都只包含一个字符。
- 从根结点到某一结点的路径上经过的字符连接起来,即为该结点对应的字符串。
- 每个结点的所有子结点包含的字符都不相同。
Trie树每一层的结点数是26^i级别的,可用用动态链表或者数组来模拟动态,空间花费不会超过单词数乘以单词长度。
问题实例:
问:一个文件中大约1万行,每行1个词,统计出现次数最高的10个词。
分析:用Trie树统计每个词出现的次数,时间复杂度O(nl)(l表示单词的平均长度),最终找出出现最频繁的前10个词(可用堆实现,时间复杂度O(nlog10))。
问:搜索引擎通过日志文件记录用户每次检索的所有查询串,每个串长度1~255字节。假设目前有1000万条记录(去重不超过300万个),统计最热门的10个查询串,要求内存少于1GB。
分析:用Trie树,观察关键词在查询串中的次数,最后用10个元素的最小堆来排序。
6.9 数据库
一般用数据库解决大数据量的增删改查。数据库索引的建立对查询速度起着至关重要的作用。
散列索引通过散列算法,对需要索引的键进行散列运算,然后将散列值存入散列表。
目前Memory和NDB Cluster存储引擎中使用。
B树、B+树等索引
B+树在B树的基础上,在每个叶节点记录指向与该叶子节点相邻的后一个叶子节点的指针,此举为了加快检索多个相邻叶节点的效率。叶节点之间就有了联系并有序了。
B*树在B+树基础上,还增加了兄弟节点之间的指针。
InnoDB存储引擎的B数索引就是使用B+树。
问题实例:
问:散列索引的效率比B树高很多,但是为什么常见数据库中一般不用散列索引而使用B树索引呢?
(
// TODO
我的答案:
1 B树是有序存储方便有序信息的查找。
2 B树的操作时间是固定的,但是散列操作遇到冲突时时间不稳定。
)
6.10 倒排索引
倒排索引(inverted index)是一种索引方法,用来存储全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
常用于搜索引擎和关键字查询等问题中。
正向索引用于存储每个文档的单词的列表,能够满足每个文档有序、频繁的全文查询和每个单词在校验文档中验证等查询。
文档指向它包含的那些单词。
反向索引则是单词指向了包含它的文档。
6.11 simhash算法
simhash作为局部敏感散列(locality sensitive hash)的一种,主要思想是降维,将高纬的特征向量映射成低维的特征向量,通过两个向量的汉明距离来判定文章是否重复或者高度近似。
在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。
simhash算法的流程
简单的说,分为5个步骤:分词、散列、加权、合并和降维。
具体见书。
应用:
比较两篇文档的相似度
网页重复的判定
第7章 机器学习
暂时不看
附录:其他题型
字符串的旋转另一个思路
m n
m+1->1
m+n->n
m->n+m
1->n+1
当 x<=m
x->n+x
当 x>m
x->x-m
